MBSDでWebアプリケーションスキャナの開発をしている寺田です。
今回は、JavaのWebサーバであるUndertowに存在したHTTPヘッダインジェクション脆弱性(CVE-2018-1067)を取り上げます。さっそく原因となったプログラムをみてみましょう。
原因となったプログラム
HTTPヘッダを出力する際、アプリケーションが処理系に渡した文字列は、最終的にバイト列に変換されます。脆弱性が修正される前のUndertowにおいて、その変換処理を行っていたプログラムが以下です。
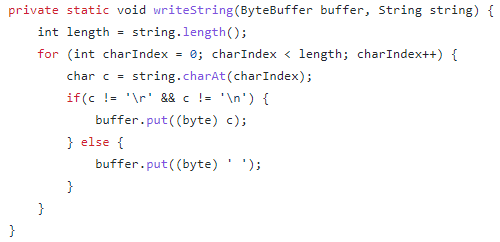
見てのとおり、引数のstringを1文字ずつバイトにしてByteBufferに入れる処理を行っており、その中で'\r'(CR)や'\n'(LF)を' '(スペース)に置換しています。これは出力するバイト列にCR/LF(0x0D, 0x0A)が含まれないようにするための処理ですが、この処理は不十分でありバイパス可能です。
このプログラムのどこが問題で、どのような攻撃が可能か分かるでしょうか?
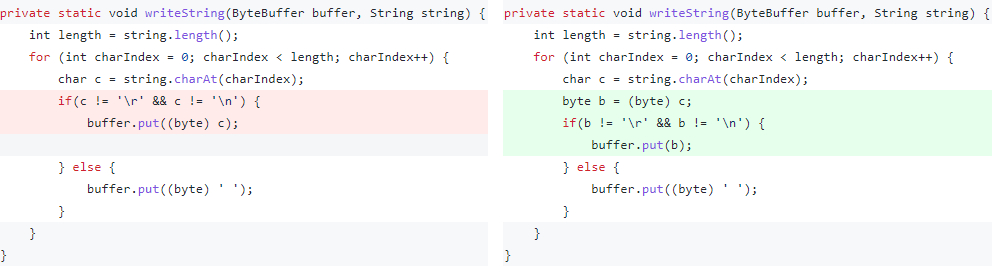
上記のプログラムだけでは分からない場合は、修正前と後のプログラムを比較すると分かりやすいかもしれません。左が修正前、右が修正後のプログラムです。
 https://github.com/undertow-io/undertow/commit/85d4478e598105fe94ac152d3e11e388374e8b86?diff=split
https://github.com/undertow-io/undertow/commit/85d4478e598105fe94ac152d3e11e388374e8b86?diff=split
問題点
修正前(左)のプログラムの問題点は、おおむね以下の2点です。
- char(16bit)をbyte(8bit)にキャストしている。
- byteへのキャストを、CR/LFのチェックの後に実施している。
攻撃者は、例えばU+560A(嘊)のような文字をプログラムに与えます。するとcharの状態におけるCR/LFのチェックには引っかからずに、その後のbyteへのキャストの際に、いわゆる縮小変換(収まりきらない上位ビットが捨てられる。ここでは0xFFとビット積を取るのと同様の処理)が行われて、以下のように0x0A(LF)ができてしまいます。
char[16bit] 560A(嘊)
⇓
byte[ 8bit] 0A(LF)
その結果、改行文字によるHTTPヘッダインジェクションが成功します。
修正後のプログラムではbyteにしてからCR/LFのチェックをしているため、HTTPヘッダインジェクションの問題はありません。
なお、上の脆弱性は先日公開した「マルチバイト文字とURL」の記事で取り上げた、filedescriptor氏の発見によるTwitterの脆弱性と同種のものです。先の記事の公開後に、いくつかの処理系について改めて調べている中でこのUndertowの脆弱性の存在を知り、「charをbyteにキャストしているJavaのソフトウェアって、意外と多いかも…」と思い記事にした次第です。
縮小変換については、JPCERT/CCの記事(NUM12-J. 数値型の縮小変換時にデータの欠損や誤解釈を引き起こさない)を参照。記事のとおり、一般的に縮小変換によって数値の絶対値や符号が変化する可能性があります。ちなみに弊社のスキャナでは、U+560A(嘊)ではなく、U+4E0A(上)を使ってこの種のテストを行っています。その方が分かりやすいですし、入力がSJISやEUC-JPであっても使用できるためです。
結論
最後にこの脆弱性から得られる教訓をまとめます。
- 大前提として、チェックの後に何らかの変換をするのは避けるべき。
- 出力するバイト列に制約をかけたいならば、文字列ではなくバイト列にした後にチェックする方がよい。
- 文字列をバイト列にする際には、ASCII/Latin1のみが含まれる場合を除いて、charをbyteにキャストする方法を取らない方がよい(通常は
String#getBytes("UTF-8")等の方が問題が生じにくい)。 - 入力に対して何らかの前提をおくならば(例えば「入力はASCII/Latin1である」との前提をおくなら)、入力が実際にその前提を満たすかチェックすべき。
もう一点付け加えると、前記事にも書いたとおり、WebアプリケーションがHTTPヘッダに値を出力する状況においては、出力に非ASCIIを含めないのが無難です。
原文始发于寺田健:Javaの文字列からバイト列への変換 | 調査研究/ブログ | 三井物産セキュアディレクション株式会社