Background 背景
In early October 2023, Google announced a new addition to their reward program, v8CTF. According to the rules: “v8CTF is a part of the Google VRP in which we reward successful exploitation attempts against a V8 version running on our infrastructure.” The nice thing about this program is that it accepts reports for vulnerabilities that have already been reported/patched, as long as you can prove that they are exploitable. I really enjoy writing exploits for v8 vulns and had not completed one for 2023, so I was excited to try and submit something. I wasn’t able to actually start working on this until a couple of weeks after the challenge had opened. However, to my surprise, nothing had been submitted yet, so there was still a chance! This post recaps a caffeine-fueled 48 hours of trial and error to defeat the latest v8 protections and retrieve the first flag from v8CTF.
2023 年 10 月初,谷歌宣布了其奖励计划的新成员 v8CTF。根据规则:“v8CTF 是 Google VRP 的一部分,我们奖励针对我们基础设施上运行的 V8 版本的成功利用尝试。这个程序的好处是它接受已经报告/修补的漏洞的报告,只要你能证明它们是可利用的。我真的很喜欢为 v8 漏洞编写漏洞,并且还没有在 2023 年完成一个漏洞,所以我很高兴能尝试提交一些东西。直到挑战开始几周后,我才真正开始研究这个问题。然而,令我惊讶的是,还没有提交任何东西,所以还有机会!这篇文章回顾了以咖啡因为燃料的 48 小时反复试验,以击败最新的 v8 保护并从 v8CTF 中取回第一个标志。
Overview 概述
This post will detail the exploit that I wrote to successfully compromise v8 version 11.7.439.3, part of Chrome version 117.0.5938.62 for Linux. I chose to exploit Issue 1472121, a vulnerability in the inline cache (IC) component. The exploit involved escaping the in-progress v8 sandbox in order to execute arbitrary shellcode, and eventually retrieve the flag hosted on the CTF infrastructure. In this post I will also link some helpful resources that I used while developing my exploit. Many techniques have become obsolete over this past year, but these posts helped provide me a good foundation, so I have included them to build a timeline and thank other v8 researchers.
这篇文章将详细介绍我为成功破坏 v8 版本 11.7.439.3 而编写的漏洞,该版本是 Chrome 版本 117.0.5938.62 for Linux 的一部分。我选择利用问题 1472121,即内联缓存 (IC) 组件中的漏洞。该漏洞涉及转义正在进行的 v8 沙盒,以执行任意 shellcode,并最终检索 CTF 基础设施上托管的标志。在这篇文章中,我还将链接一些我在开发漏洞利用时使用的有用资源。在过去的一年里,许多技术已经过时了,但这些帖子为我提供了一个良好的基础,所以我把它们包括在内,以建立一个时间表,并感谢其他 v8 研究人员。
The Vulnerability 漏洞
I found the vulnerability which I chose to exploit by searching the git log for any issues that looked easily exploitable. One reason that Issue 1472121 appeared so promising was that the commit to patch it had a regression test attached which showed the bug being triggered, as well as corrupting an object’s metadata. Since I was focused on moving to exploitation as quickly as possible, I initially took the regression test and immediately began to work on gaining code execution. However, since it is a useful exercise, I will go through the details of the vulnerability here. The bug report was locked when I first worked on this, but has since been derestricted and can provide additional details. First, let’s look at the commit message:
我通过在 git 日志中搜索任何看起来很容易利用的问题来找到我选择利用的漏洞。Issue 1472121 看起来如此有希望的一个原因是,修补它的提交附加了一个回归测试,该测试显示该错误被触发,以及损坏对象的元数据。由于我专注于尽快转向开发,因此我最初参加了回归测试,并立即开始努力获得代码执行。但是,由于这是一项有用的练习,因此我将在此处介绍该漏洞的详细信息。当我第一次处理这个问题时,错误报告被锁定了,但后来被取消了限制,可以提供更多细节。首先,让我们看一下提交消息:
[ic] Fix clone ic when the target has fewer inobject properties The clone ic miss handler did not correctly anticipate that the target map chosen by the runtime clone implementation can pick a target map with fewer inobject properties. In this case inobject properties need to be moved to normal properties, which the fast case cannot. Bug: chromium:1472121 |
The commit message provides a very detailed description of the vulnerability, but it will be useful to see how this plays out in a debugger. Specifically I want to look at the maps of various objects and their property layouts. I prefer to look at vulnerabilities from a top-down perspective so I’ll begin with the, slightly modified, regression test:
提交消息提供了对漏洞的非常详细的描述,但了解这在调试器中的表现会很有用。具体来说,我想查看各种对象的映射及其属性布局。我更喜欢从自上而下的角度来看待漏洞,因此我将从稍作修改的回归测试开始:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
// Copyright 2023 the V8 project authors. All rights reserved. // Use of this source code is governed by a BSD-style license that can be // found in the LICENSE file. let subject = {p0: 1, p1: 1, p2: 1, p3: 1, p4: 1, p5: 1, p6: 1, p7: 1, p8: 1}; subject.p9 = 1; function throwaway() { return {...subject, __proto__: null}; } for (let j = 0; j < 100; ++j) { // IC throwaway(); } for (let key in subject) { subject[key] = {}; } function func() { return {...subject, __proto__: null}; } for (let j = 0; j < 100; ++j) { // IC corrupted = func(); } corrupted.p9 = 0x42424242 >> 1; %DebugPrint(corrupted); |
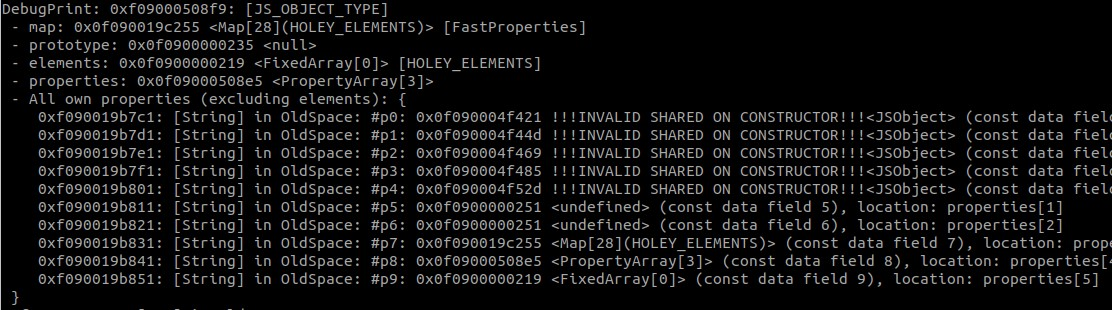
Running this code does indeed cause a debug check or crash on the print statement. In order to get a better idea of what happened, we can remove the write to corrupted.p9 and look at the layout of corrupted. Based on this output, it seems as though some properties overlap with the object itself, which can be confirmed in GDB. This also explains why we get a crash, since corrupted.p9 overlaps with the elements store pointer and changing this value leads to problems while printing the object.
运行此代码确实会导致 print 语句的调试检查或崩溃。为了更好地了解发生了什么,我们可以删除 write to corrupted.p9 并查看 corrupted 的布局。根据此输出,似乎某些属性与对象本身重叠,这可以在 GDB 中确认。这也解释了为什么我们会遇到崩溃,因为 corrupted.p9 与元素存储指针重叠,更改此值会导致打印对象时出现问题。
There are some useful debugging features that can be introduced to a script in v8 by running it with the
--allow-natives-syntaxflag. For example, some functions that I added to my script were%SystemBreak()and%DebugPrint(object). There is also a gdbinit file which adds extra debugger commands.
在 v8 中,可以通过使用--allow-natives-syntax标志运行脚本来引入一些有用的调试功能。例如,我添加到脚本中的一些函数是%SystemBreak()和%DebugPrint(object)。还有一个 gdbinit 文件,它添加了额外的调试器命令。
Since there is an incorrect properties layout here, the first important area to cover is how this storage works.
由于此处的属性布局不正确,因此要涵盖的第一个重要领域是此存储的工作原理。
Object Properties 对象属性
For a great introduction to how v8 does property storage, I recommend reading Fast properties in V8. The important takeaway from this article is that v8 utilizes both in-object properties as well as a property store, and the location of properties is specified by the object’s map. In this article we see that “the number of in-object properties is predetermined by the initial size of the object. If more properties get added than there is space in the object, they are stored in the properties store.” So let’s take a look at the layout of our subject object.
有关 v8 如何进行属性存储的精彩介绍,我建议阅读 V8 中的快速属性。本文的重要要点是,v8 既利用了对象内属性,也利用了属性存储,并且属性的位置由对象的映射指定。在本文中,我们看到“对象内属性的数量是由对象的初始大小预先确定的。如果添加的属性多于对象中的空间,则这些属性将存储在属性存储中。因此,让我们看一下对象 subject 的布局。
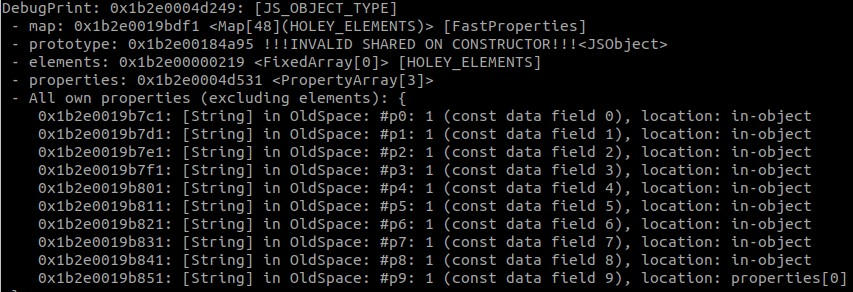
The first image is the %DebugPrint(subject) output, in which we see that subject has 9 in-object properties, and 1 located at properties[0]. This tracks with what we expect, since the object was created with 9 properties initially, and 1 was added later. In GDB, we can see how the properties are stored. (Note: the value 1 is stored as a 2 because SMIs are shifted to the left 1 bit).
第一张图片是 %DebugPrint(subject) 输出,我们看到它 subject 有 9 个对象内属性,其中 1 个位于 properties[0] 。这与我们的预期相符,因为该对象最初是使用 9 个属性创建的,后来添加了 1 个属性。在 GDB 中,我们可以看到属性是如何存储的。(注意:值 1 存储为 2,因为 SMI 向左移动了 1 位)。

So the first clue we have that something is wrong lies in the fact that the map of our source object expects 9 in-object properties, but the corrupted object only expects there to be 4. With debugging statements, I was able to determine that subject kept its layout after all properties were changed to empty objects. Additionally, all calls to throwaway() and func() returned objects with the same layout until after the IC runtime clone implementation changed to the fast path. This makes a lot of sense given the commit message, so the next piece to examine is the source code and what happens in the IC clone functions.
因此,我们发现有问题的第一个线索在于,源对象的映射需要 9 个对象内属性,但 corrupted 对象只期望有 4 个。通过调试语句,我能够确定在所有属性更改为空对象后保留 subject 其布局。此外,在 IC 运行时克隆实现更改为快速路径之前,所有对具有相同布局的对象的调用和 func() 返回的 throwaway() 对象。考虑到提交消息,这很有意义,因此接下来要检查的是源代码以及 IC 克隆函数中发生的情况。
While the bug exists in the IC code, I do not think a lot of background information of this component as a whole is needed to understand the vulnerability, so I will not discuss it at length. There are already a good amount of write-ups of previous bugs found in the inline cache, my favorite of which is The Chromium super (inline cache) type confusion by Man Yue Mo. Another go-to article for this topic is JavaScript engine fundamentals: Shapes and Inline Caches by Mathias Bynens and Benedikt Meurer. At a high level, the IC is meant to speed up property lookups by caching an object property’s offset within the bytecode itself. It is responsible for collecting some profiling data on accessing an object and using that to speed up certain operations, such as object cloning.
Source Code
For both throwaway() and func(), the generated bytecode shows that there is a CloneObject instruction. Here is the relevant Ignition handler for that opcode:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
// CloneObject <source_idx> <flags> <feedback_slot> // // Allocates a new JSObject with each enumerable own property copied from // {source}, converting getters into data properties. IGNITION_HANDLER(CloneObject, InterpreterAssembler) { TNode<Object> source = LoadRegisterAtOperandIndex(0); TNode<Uint32T> bytecode_flags = BytecodeOperandFlag8(1); TNode<UintPtrT> raw_flags = DecodeWordFromWord32<CreateObjectLiteralFlags::FlagsBits>(bytecode_flags); TNode<Smi> smi_flags = SmiTag(Signed(raw_flags)); TNode<TaggedIndex> slot = BytecodeOperandIdxTaggedIndex(2); TNode<HeapObject> maybe_feedback_vector = LoadFeedbackVector(); TNode<Context> context = GetContext(); TNode<Object> result = CallBuiltin(Builtin::kCloneObjectIC, context, source, smi_flags, slot, maybe_feedback_vector); SetAccumulator(result); Dispatch(); } |
The path from code generated to handle this instruction to the patched function is Accessor Assembler::GenerateCloneObjectIC() -> RUNTIME_FUNCTION(Runtime_CloneObjectIC_Miss) -> CanFastCloneObjectWithDifferentMaps(). The purpose of the vulnerable function is to determine if a given target map can be used for a clone operation without needing to change the property layout, based on the source map. This is important because of what a comment within the function states: “the clone IC blindly copies the bytes from source object to result object.” Therefore, certain guarantees have to be made about the chosen map so that the target object will have a compatible property layout with the source object. In the original code, there was the check for source_map->instance_size() >= target_map->instance_size(), which has since been removed and replaced with more detailed checks. This check was lacking in part because the instance size does guarantee a particular property layout, which I will discuss later. The question now is how to get an incompatible target map to pass this check.
从为处理此指令而生成的代码到修补函数的路径是 Accessor Assembler::GenerateCloneObjectIC() -> RUNTIME_FUNCTION(Runtime_CloneObjectIC_Miss) -> CanFastCloneObjectWithDifferentMaps()。易受攻击的函数的目的是根据源映射确定给定的目标映射是否可以用于克隆操作,而无需更改属性布局。这很重要,因为函数中的注释指出:“克隆 IC 盲目地将字节从源对象复制到结果对象。因此,必须对所选映射做出某些保证,以便目标对象具有与源对象兼容的属性布局。在原始代码中,有 的 source_map->instance_size() >= target_map->instance_size() 检查,后来被删除并替换为更详细的检查。缺少此检查的部分原因是实例大小确实保证了特定的属性布局,我将在后面讨论。现在的问题是如何让不兼容的目标映射通过此检查。
It is helpful to look at the Runtime function and see how it will call the vulnerable function. CanFastCloneObjectWithDifferentMaps() is only called if we are in the case of FastCloneObjectMode::kDifferentMap. According to a code comment, this happens when the clone has an empty object literal map. In our specific example, this happens because the cloned object is instantiated with __proto__: null, and GetCloneModeForMap() returns FastCloneObjectMode::kDifferentMap for this construct.
查看 Runtime 函数并查看它将如何调用易受攻击的函数会很有帮助。 CanFastCloneObjectWithDifferentMaps() 只有当我们处于 的情况下 FastCloneObjectMode::kDifferentMap ,才会调用。根据代码注释,当克隆具有空对象文本映射时,会发生这种情况。在我们的特定示例中,发生这种情况是因为克隆的对象是使用 __proto__: null 实例化的,并 GetCloneModeForMap() 返回 FastCloneObjectMode::kDifferentMap 此构造。
1 2 3 4 5 6 7 8 9 10 11 12 |
case FastCloneObjectMode::kDifferentMap: { Handle<Object> res; ASSIGN_RETURN_FAILURE_ON_EXCEPTION(isolate, res, CloneObjectSlowPath(isolate, source, flags)); Handle<Map> result_map(Handle<HeapObject>::cast(res)->map(), isolate); if (CanFastCloneObjectWithDifferentMaps(source_map, result_map, isolate)) { DCHECK(result_map->OnlyHasSimpleProperties()); nexus.ConfigureCloneObject(source_map, MaybeObjectHandle(result_map)); } else { nexus.ConfigureMegamorphic(); } return *res; } |
At this point, CanFastCloneObjectWithDifferentMaps() is used to see if we can switch to the fast path. The next item to examine is how the target map is selected in the first place. Based on the code above, we see that the target object is returned by CloneObjectSlowPath().
1 2 3 4 5 |
static MaybeHandle<JSObject> CloneObjectSlowPath(Isolate* isolate, Handle<Object> source, int flags) { Handle<JSObject> new_object; if (flags & ObjectLiteral::kHasNullPrototype) { new_object = isolate->factory()->NewJSObjectWithNullProto(); ... |
If the target has a null prototype, such as in the regression test, then we call NewJSObjectWithNullProto(). A quick test shows that creating an empty object causes it to start with space for 4 in-object properties. When objects are first instantiated, they are given a certain amount of unused space for properties, even if they have yet to be assigned (see Slack tracking in V8), so this makes sense. And now the layout mismatch makes sense as well. A target object is created without space for a lot of in-object properties because they do not exist yet, and its instance size is smaller than the source object and therefore passes the check.
如果目标有一个空原型,例如在回归测试中,那么我们调用 NewJSObjectWithNullProto()。快速测试表明,创建一个空对象会导致它以 4 个对象内属性的空间开始。当对象首次实例化时,即使尚未分配属性,也会为它们提供一定数量的未使用空间(参见 V8 中的 Slack 跟踪),因此这是有道理的。现在,布局不匹配也是有道理的。创建目标对象时没有空间容纳大量对象内属性,因为它们尚不存在,并且其实例大小小于源对象,因此通过了检查。
This is how a target map is chosen that will switch our code to the fast path. Now, when the source object is copied, the code tries to place 9 properties within the target object. However, the target map only expects 4 properties to be there, so it believes properties 5-10 will be in the property store. The property store was copied from the source as well, and is too small for this. So when we access certain properties, we will look beyond the bounds of the property store, which is allocated just in front of the target object. The slow path would have made more room in the object and updated the map, but the fast path does not.
这就是选择目标地图的方式,它将我们的代码切换到快速路径。现在,当复制源对象时,代码会尝试在目标对象中放置 9 个属性。但是,目标地图仅期望有 4 个属性,因此它认为属性 5-10 将位于属性存储中。属性存储也是从源复制的,对于此来说太小了。因此,当我们访问某些属性时,我们将超越属性存储的边界,该属性存储在目标对象的前面。慢速路径会在对象中腾出更多空间并更新地图,但快速路径不会。
The last thing that I was curious about was why we needed to change the values of all the properties of subject and then have the IC run again. I found that this was important for the last check in CanFastCloneObjectWithDifferentMaps(). Basically, running the IC twice is needed for the target map to have more generic representation handling. It is also important that every property changes in the object that is being cloned, and it must be from either smi->heap object or heap object->smi. The code below shows how this check is implemented. Once this check passes on the second IC run for func(), the function returns true, and we begin to use the fast path for cloning the object.
我好奇的最后一件事是,为什么我们需要更改所有属性 subject 的值,然后让IC再次运行。我发现这对于最后一次入住 CanFastCloneObjectWithDifferentMaps() 很重要。基本上,需要运行两次 IC 才能使目标映射具有更通用的表示处理。同样重要的是,要克隆的对象中的每个属性都发生了变化,并且它必须来自 smi->heap object 或 heap object->smi 。下面的代码显示了如何实现此检查。一旦此检查通过第二次 IC 运行,该函数将返回 true func() ,我们开始使用快速路径来克隆对象。
1 2 3 4 5 6 7 8 9 |
for (InternalIndex i : target_map->IterateOwnDescriptors()) { PropertyDetails details = descriptors->GetDetails(i); PropertyDetails target_details = target_descriptors->GetDetails(i); DCHECK_EQ(details.kind(), PropertyKind::kData); DCHECK_EQ(target_details.kind(), PropertyKind::kData); if (!details.representation().MostGenericInPlaceChange().Equals(target_details.representation())) { return false; } } |
Summary
The IC attempts to optimize the code to clone an object if it can determine enough information about the source map and expected target map. This fast path will simply copy bytes from the source object to the target object. It was possible to create a source object with several in-object properties and force a target to be chosen that does not have space for the in-object properties. Due to the mismatch, the target map allows for invalid property accesses that can be used to corrupt an object.
Patch
The patch modifies the checks in CanFastCloneObjectWithDifferentMaps() so that it does not simply look at the size of the property stores for both maps, but also verifies that there is room in the target object for all in-object properties from the source.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
if (source_map->instance_type() != JS_OBJECT_TYPE || target_map->instance_type() != JS_OBJECT_TYPE || - source_map->instance_size() < target_map->instance_size() || !source_map->OnlyHasSimpleProperties() || !target_map->OnlyHasSimpleProperties()) { return false; } - if (target_map->instance_size() > source_map->instance_size()) { + // Check that the source inobject properties are big enough to initialize all + // target slots, but not too big to fit. + int source_inobj_properties = source_map->GetInObjectProperties(); + int target_inobj_properties = target_map->GetInObjectProperties(); + int source_used_inobj_properties = + source_inobj_properties - source_map->UnusedPropertyFields(); + if (source_inobj_properties < target_inobj_properties || + source_used_inobj_properties > target_inobj_properties) { return false; } |
This patch was actually incomplete, and another check was added to this function as well (see related issue).
The exploit
While there have been many examples of v8 bugs being turned into exploits, I knew that this was going to be slightly more challenging because of the movement towards a full implementation of the v8 sandbox. While it is not yet complete, there are a decreasing number of 64-bit pointers and means to gain arbitrary code execution. Because of this, I started out with no clear path to exploitation, and needed to spend time experimenting with different methods. Here I will cover the various things I tried, what worked, and what did not.
虽然有很多 v8 错误被转化为漏洞的例子,但我知道这将更具挑战性,因为 v8 沙盒正在朝着全面实现的方向发展。虽然它尚未完成,但 64 位指针和获得任意代码执行的方法的数量正在减少。正因为如此,我一开始没有明确的开发途径,需要花时间尝试不同的方法。在这里,我将介绍我尝试过的各种事情,哪些有效,哪些无效。
Links to my code in order to follow along with the writeup:
链接到我的代码,以便按照文章进行操作:
V8 Sandbox V8 沙盒
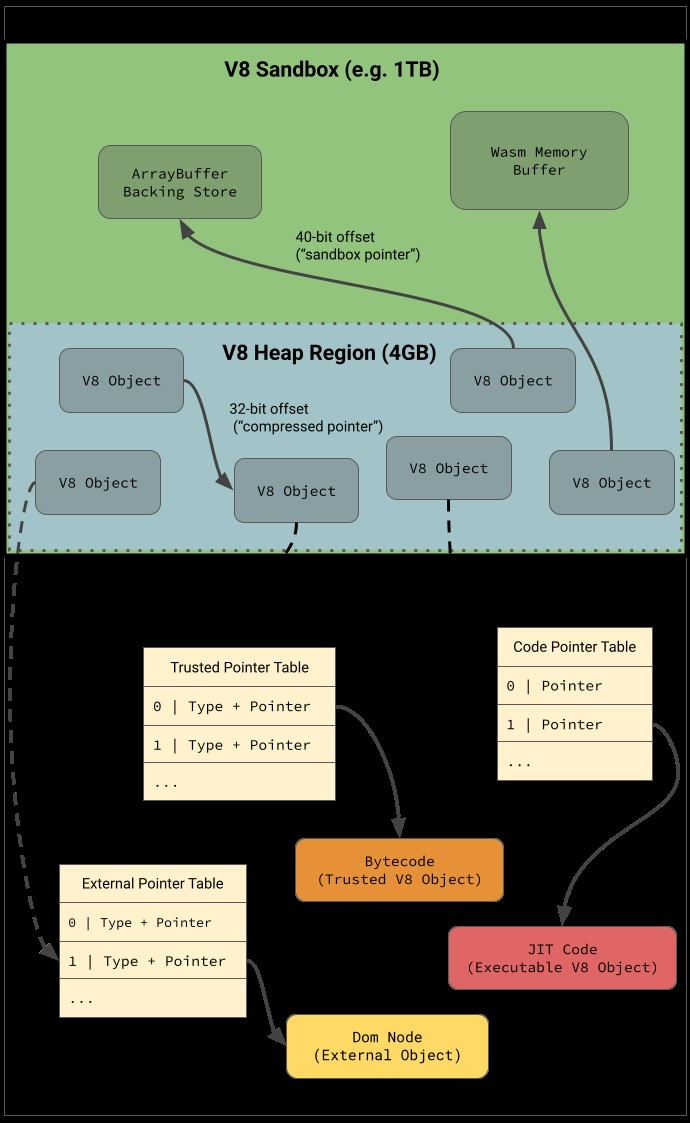
v8 has been using pointer compression for quite some time, meaning that isolates have a smaller address space for their heap, and can mostly utilize 32-bit compressed pointers to increase efficiency. However, various 64-bit pointers have remained in the isolate’s heap over time, and these have been abused to achieve arbitrary read/write and code execution within the larger process address space. Some notable ones for exploitation were pointers to ArrayBuffer backing stores, code objects, and the Wasm memory area. The v8 sandbox is an effort to rid the isolate of these pointers, as well as other items that can be corrupted to gain code execution, by removing them from a 40-bit sandboxed region (see diagram below). Part of this includes modifying objects like ArrayBuffers to only use 40-bit “sandboxed pointers” as offsets for their backing store, relative to the sandbox base. The project is a very large undertaking and is still not completely finished. However, there has been a great deal of progress recently and it has necessitated new exploitation techniques to be looked at over the past year. Therefore, the challenge was to figure out what sensitive pieces still existed within the sandbox.
V8 使用指针压缩已经有一段时间了,这意味着隔离的堆地址空间较小,并且主要可以利用 32 位压缩指针来提高效率。但是,随着时间的推移,各种 64 位指针仍保留在隔离的堆中,并且这些指针已被滥用,以在较大的进程地址空间内实现任意读/写和代码执行。一些值得注意的漏洞利用是指向 ArrayBuffer 支持存储、代码对象和 Wasm 内存区域的指针。v8 沙盒旨在通过从 40 位沙盒区域中删除这些指针以及其他可能被损坏以获得代码执行的项目(见下图)来消除这些指针的隔离。其中一部分包括修改 ArrayBuffers 等对象,使其仅使用 40 位“沙盒指针”作为其后备存储相对于沙盒基础的偏移量。该项目是一项非常庞大的任务,尚未完全完成。然而,最近取得了很大进展,在过去一年中需要研究新的开发技术。因此,挑战在于弄清楚沙盒中还存在哪些敏感部分。
Recent work 近期工作
Just before v8CTF was announced, there were a few really great write-ups that came out detailing some modern v8 exploitation techniques. The first was the v8box write-up from Google CTF 2023. This challenge involved exploiting v8 using the memory corruption API. The solution provided by the author overwrote Ignition bytecode located within the v8 heap in order to gain control of the stack pointer. At this point, a ROP chain could be used to pwn the process. The next article was Getting RCE in Chrome with incorrect side effect in the JIT compiler by Man Yue Mo. The technique they used was injecting shellcode into a JIT function by returning an array of float values. Then, their exploit modified the code object for the function so that calling it would jump to a slightly different offset than was intended, and the new code path would execute arbitrary instructions. Finally, Exploiting Zenbleed from Chrome by Trent Novelly showed a similar technique to the last one, but he used the JIT function to copy code from the isolate heap to the Wasm code area. This is a more generic implementation, allowing for lengthier shellcode to be used without the need to encode it with short jumps. This general technique goes back though, as both authors cite this writeup by 2019, who first created it.
就在 v8CTF 发布之前,有一些非常棒的文章详细介绍了一些现代 v8 开发技术。第一个是 Google CTF 2023 的 v8box 文章。这一挑战涉及使用内存损坏 API 利用 v8。作者提供的解决方案覆盖了位于 v8 堆内的 Ignition 字节码,以便获得对堆栈指针的控制。此时,可以使用 ROP 链来 pwn 该过程。下一篇文章是 Getting RCE in Chrome with incorrect side effect in the JIT compiler by Man Yue Mo。他们使用的技术是通过返回浮点值数组将 shellcode 注入 JIT 函数。然后,他们的漏洞修改了函数的代码对象,以便调用它将跳转到与预期略有不同的偏移量,并且新的代码路径将执行任意指令。最后,Trent Novelly 的 Exploiting Zenbleed from Chrome 展示了与上一个类似的技术,但他使用 JIT 函数将代码从隔离堆复制到 Wasm 代码区域。这是一个更通用的实现,允许使用更长的 shellcode,而无需使用短跳转对其进行编码。不过,这种通用技术可以追溯到 2019 年,因为两位作者都引用了这篇文章,谁首先创建了它。
While these write-ups were very helpful to learn from, new sandbox improvements meant that none of these techniques would work completely since I immediately saw that the Function object no longer pointed directly to JIT code. :’(
虽然这些文章非常有帮助,但新的沙盒改进意味着这些技术都不能完全起作用,因为我立即看到该 Function 对象不再直接指向 JIT 代码。:'(
Getting Read/Write Within the Sandbox
在沙盒中获取读/写
While escaping the sandbox was going to be the biggest challenge, I knew that any attempt was going to require arbitrary read/write within the 40-bit sandbox. My initial primitive was the ability to overwrite an object’s metadata on the v8 heap, so I modified the regression test code to overwrite the length of an array. Now, I could use this array to read and overwrite adjacent objects. The object that I chose to overwrite was an ArrayBuffer because of its ability to easily read/write various byte sizes, as well as the fact that it has a sandboxed pointer for its backing store that I can modify. I also placed a property in my victim object that is a pointer to another object. I could use my OOB read from the initially corrupted array to read this pointer, giving me an addr_of primitive as well.
虽然逃离沙盒将是最大的挑战,但我知道任何尝试都需要在 40 位沙盒中进行任意读/写。我最初的原语是能够在 v8 堆上覆盖对象的元数据,因此我修改了回归测试代码以覆盖数组的长度。现在,我可以使用这个数组来读取和覆盖相邻的对象。我选择覆盖的对象是 ArrayBuffer,因为它能够轻松读取/写入各种字节大小,并且它有一个沙盒指针用于我可以修改的后备存储。我还在我的受害者对象中放置了一个属性,该属性是指向另一个对象的指针。我可以使用从最初损坏的数组中读取的 OOB 来读取此指针,从而也为我提供一个 addr_of 基元。
Looking back, I would probably do this differently, but I wanted to include the original code that I used to retrieve the flag. As a result, this post will describe what I did and not necessarily what is ideal. Hopefully later submissions will have better code that I have since fixed up.
Gaining More Primitives 获得更多基元
Getting to this point was very straightforward, but updates to the sandbox meant that creating a full exploit was going to require a novel exploitation technique. The go-to method for exploiting v8 in all of the examples that I could find was to corrupt a code object; however, this was recently patched. Based on the “Recent Work” section I had three areas that I wanted to examine.
达到这一点非常简单,但对沙盒的更新意味着创建完整的漏洞利用将需要一种新颖的漏洞利用技术。在我能找到的所有示例中,利用 v8 的首选方法是损坏代码对象;但是,最近对此进行了修补。根据“最近的工作”部分,我有三个方面想研究。
1. What is left of the Code Object on the heap?
1. 堆上的代码对象还剩下什么?
Not much. At least not a 64-bit pointer or a helpful offset. I spent a lot of time looking through structures in the Function object that would be useful to modify or read, but I began to realize that this would not be the path of least resistance. I knew that I could still write ROP gadgets into the JIT code, but I was unsure of how to find the code’s address, and also how to jump to it.
不多。至少不是 64 位指针或有用的偏移量。我花了很多时间查看 Function 对象中对修改或阅读有用的结构,但我开始意识到这不是阻力最小的路径。我知道我仍然可以将 ROP 小工具写入 JIT 代码中,但我不确定如何找到代码的地址,以及如何跳转到它。
2. Can we take control of RSP?
2. 我们能控制退休储蓄计划吗?
This technique seemed more promising as I found that Ignition bytecode was still stored in the v8 heap. I was also able to use my earlier primitives to retrieve the address of the bytecode and modify it. I used the Google CTF writeup mentioned before in order to take control of rsp and have it point to an area of the v8 heap that I could write to in order to assemble my ROP chain. However, there were a couple challenges while doing this. First, there were various checks and writes in the trampoline code that meant that the fake object which I passed as my argument needed to have specific values at specific offsets. This took some troubleshooting in GDB, and had to be redone when I tested the exploit against the chrome binary, as the offsets seemed to change slightly. The second issue was that rsp is set to the value of the argument that I give the function, which happens to be an object. Objects in v8 have their address end in a 1, because of pointer tagging. This meant that my stack would not be properly aligned. Thankfully, I was also able to specify the initial return address from running the bytecode before relying on my ROP chain, which I could point to a gadget that aligns rsp.
这种技术似乎更有前途,因为我发现 Ignition 字节码仍然存储在 v8 堆中。我还能够使用我早期的原语来检索字节码的地址并对其进行修改。我使用了前面提到的 Google CTF 写入来控制 rsp 并让它指向我可以写入的 v8 堆区域以组装我的 ROP 链。然而,在这样做时遇到了一些挑战。首先,蹦床代码中有各种检查和写入,这意味着我作为参数传递的假对象需要在特定偏移量处具有特定值。这需要在 GDB 中进行一些故障排除,当我针对 chrome 二进制文件测试漏洞利用时,必须重做,因为偏移量似乎略有变化。第二个问题是 rsp 被设置为我给函数的参数的值,而该函数恰好是一个对象。v8 中的对象的地址以 结尾 1 ,因为指针标记。这意味着我的堆栈将无法正确对齐。值得庆幸的是,在依赖我的 ROP 链之前,我还能够通过运行字节码来指定初始返回地址,我可以将其指向对齐 rsp 的小工具。
Getting control of the stack meant that I could jump to JIT code, if I had an address. I continued searching for pointers to JIT code, as well as any pointers into the d8 text section or libraries. I was able to find 64-bit heap addresses, but offsets did not seem reliable enough to create a ROP chain. Therefore, I chose to look for other potential areas to store/find ROP gadgets.
获得堆栈的控制权意味着如果我有一个地址,我可以跳转到 JIT 代码。我继续搜索指向 JIT 代码的指针,以及指向 d8 文本部分或库的任何指针。我能够找到 64 位堆地址,但偏移量似乎不够可靠,无法创建 ROP 链。因此,我选择寻找其他潜在区域来存储/查找 ROP 小工具。
3. Can we still execute our shellcode in the Wasm region?
3. 我们还能在 Wasm 区域执行我们的 shellcode 吗?
An old path to running arbitrary shellcode in v8 was overwriting the Wasm code region. This area is marked rwx, which is perfect for exploitation. However, it exists outside of the sandbox, so I knew I wouldn’t be able to directly write any code here. However, the ability to use overwritten JIT code seemed even more impossible at this point, and this gave me an idea. What if we could write gadgets into the Wasm code, just like the JIT function code? The WebAssembly.Instance object on the heap still had a 64-bit pointer to where the code is located, so I would know where to jump. This actually turned out to be pretty straightforward, and I encoded the x86 instructions into store operations in WebAssembly text (WAT) code. I could have attempted to link the gadgets together with short jumps, but since I already had the ability to use multiple gadgets I just decided to write them separately. I also chose to employ the idea from Exploiting Zenbleed from Chrome to create a generic copy from the isolate heap to the Wasm area, meaning that I could run arbitrary shellcode with the same encoded ROP gadgets. Now I had the gadgets for my ROP chain, their addresses, and arguments to copy arbitrary shellcode to a known Wasm address. The last step was to end my ROP chain with the address where I copied the shellcode, execute it, and print the flag.
在 v8 中运行任意 shellcode 的旧路径是覆盖 Wasm 代码区域。这个区域被标记为 rwx,非常适合开发。但是,它存在于沙盒之外,所以我知道我无法直接在这里编写任何代码。然而,在这一点上,使用覆盖的 JIT 代码的能力似乎更加不可能,这给了我一个想法。如果我们能像 JIT 函数代码一样,将小工具写入 Wasm 代码会怎样?堆上的 WebAssembly.Instance 对象仍然有一个指向代码所在位置的 64 位指针,因此我知道要跳到哪里。这实际上非常简单,我将 x86 指令编码为 WebAssembly 文本 (WAT) 代码中的存储操作。我本可以尝试通过短跳将这些小工具连接在一起,但由于我已经有能力使用多个小工具,所以我决定将它们分开编写。我还选择采用 Chrome 中的 Zenbleed 中的想法来创建从隔离堆到 Wasm 区域的通用副本,这意味着我可以使用相同的编码 ROP 小工具运行任意 shellcode。现在我有了我的 ROP 链的小工具、它们的地址和参数,可以将任意 shellcode 复制到已知的 Wasm 地址。最后一步是用我复制 shellcode 的地址结束我的 ROP 链,执行它并打印标志。
Below is the .wat file that I used to encode my gadgets. The offsets from the Wasm code base were consistent across runs.
下面是我用来对我的小工具进行编码 .wat 的文件。Wasm 代码库的偏移量在运行中是一致的。
(module
(type (;0;) (func (param i32)))
(func (;0;) (type 0) (param i32)
local.get 0
i64.const 0xc359c35ec35f <- pop rdi; ret; pop rsi; ret; pop rcx; ret;
i64.store
local.get 0
i64.const 0xc3a4f3 <- rep movs BYTE PTR es:[rdi],BYTE PTR ds:[rsi]; ret;
i64.store
local.get 0
i64.const 0xc310658d48 <- lea rsp,[rbp+0x10]; ret;
i64.store)
(table (;0;) 0 funcref)
(memory (;0;) 1)
(export "memory" (memory 0))
(export "func" (func 0)))
|
I also found that overwriting the 64-bit pointer of the
wasmInstanceobject before executing the Wasm code would cause the process to jump to any address I specified. However, I realized this too late and already made enough progress with pivoting the stack that it did not seem helpful anymore.
我还发现,在执行 Wasm 代码之前覆盖wasmInstance对象的 64 位指针会导致进程跳转到我指定的任何地址。然而,我意识到这一点为时已晚,并且已经在调整堆栈方面取得了足够的进展,以至于它似乎不再有用了。
Completed Roadmap 完成的路线图
- Use the vulnerability to modify v8 heap objects to achieve read, write, and addr_of primitives within the sandbox
利用该漏洞修改v8堆对象,实现沙箱内读写addr_of原语 - Load WebAssembly with useful gadgets for ROP (done by using store instructions with constants that are encoded instructions) that we can leak the addresses for from the WasmInstance object
使用 ROP 的有用小工具加载 WebAssembly(通过使用带有编码指令的常量的存储指令来完成),我们可以从 WasmInstance 对象泄漏地址 - Create a byte array with the final x86 payload to run
创建一个字节数组,其中包含要运行的最终 x86 有效负载 - Create and modify v8 bytecode to take control of rsp/rbp
创建和修改 v8 字节码以控制 rsp/rbp - Use our controlled stack to ROP and copy the byte array to the Wasm rwx page and execute
使用我们受控的堆栈进行 ROP 并将字节数组复制到 Wasm rwx 页面并执行
Success 成功
And now all that is left is to run the exploit on remote.
现在剩下的就是在远程上运行漏洞利用。
Acknowledgments 确认
I first wanted to thank the researchers whose detailed write-ups greatly helped me to create my own exploit for this challenge; including Man Yue Mo, Trent Novelly, and 2019. I also wanted to give a huge thank you to the team at Google/Stephen Röttger for starting this program and providing an awesome opportunity to further incentivize research into v8 security!
我首先要感谢研究人员,他们的详细文章极大地帮助我为这一挑战创造了自己的漏洞;包括 Man Yue Mo、Trent Novelly 和 2019。我还想非常感谢 Google/Stephen Röttger 的团队启动了这个项目,并提供了一个绝佳的机会来进一步激励对 v8 安全的研究!
Conclusion 结论
This competition was a great opportunity to learn about recent v8 exploits and find a new way to escape the partial sandbox. Some of the techniques I used have already been patched, so I am excited to see what methods are used for v8CTF in the future.
这次比赛是一个很好的机会,可以了解最近的 v8 漏洞,并找到一种逃离部分沙盒的新方法。我使用的一些技术已经打了补丁,所以我很高兴看到将来 v8CTF 会使用什么方法。
References 引用
- Expanding our exploit reward program to Chrome and Cloud
将漏洞利用奖励计划扩展到 Chrome 和 Cloud - Fast properties in V8 by Camillo Bruni
V8 by Camillo Bruni的住宿 - The Chromium super (inline cache) type confusion by Man Yue Mo
The Chromium super(内联缓存)类型混淆,作者:Man Yue Mo - JavaScript engine fundamentals: Shapes and Inline Caches by Mathias Bynens and Benedikt Meurer
JavaScript 引擎基础知识:形状和内联缓存,作者:Mathias Bynens 和 Benedikt Meurer - Slack tracking in V8 by Michael Stanton
V8 中的松弛跟踪,作者:Michael Stanton - Pointer Compression in V8 by Igor Sheludko and Santiago Aboy Solanes
V8 中的指针压缩,作者:Igor Sheludko 和 Santiago Aboy Solanes - V8 Sandbox – High-Level Design Doc
V8 沙盒 – 高级设计文档 - v8box write-up V8box 写入
- Getting RCE in Chrome with incorrect side effect in the JIT compiler by Man Yue Mo
在 Chrome 中获取 RCE,并在 JIT 编译器中出现不正确的副作用,作者:Man Yue Mo - Exploiting Zenbleed from Chrome by Trent Novelly
利用 Trent Novelly 的 Chrome 中的 Zenbleed - Dice CTF Memory Hole: Breaking V8 Heap Sandbox by 2019
骰子 CTF 内存洞:到 2019 年打破 V8 堆沙盒
原文始发于madStacks:Start Your Engines – Capturing the First Flag in Google’s New v8CTF
转载请注明:Start Your Engines – Capturing the First Flag in Google’s New v8CTF | CTF导航