本篇文章分析的源码地址为:https://github.com/ethereum/go-ethereum
分支:master
commit id: 257bfff316e4efb8952fbeb67c91f86af579cb0a
引言
所有的区块链项目中,区块所组成的数据结构都是核心之一。之所以叫“区块链”,正是因为这些项目都是以链式结构组织所有区块的,以太坊也不例外。当然除了链式结构以外,以太坊中还加入了一些其它功能,比如叔块、主链与侧链的维护等。下面我们来详细分析一下这些功能,相信看完以后,你会更有信心写一个自己的区块链结构了。
在正式深入到各功能中之前,我们先简单说明一下源码的组织,以方便您能快速了解代码结构。
注意在本篇文章里,我们提到“区块链”这个词时,一般都是指它的狭义上的意义,即表示区块和链组成的一种数据结构。如果不是这个意义,我会用“区块链项目”这个词若进行特别的说明。
源码简介
以太坊中关于区块链结构的代码位于三个目录下:
- core目录(仅包含目录下的go文件)
- core/rawdb目录
- light目录
core目录下的go文件包含了几乎所有重要功能,是以太坊区块链的核心代码。其中blockchain.go中实现的BlockChain结构及方法是核心实现;headerchain.go中实现的HeaderChain实现了对区块头的管理。
core/rawdb目录实现了从数据库中读写所有区块结构的方法。从这些代码中可以看出区块链在代码中是如何组织的。
light目录下的代码实现了light同步模式(后面会讲到)下区块链的组织和维护。
什么是区块和链
我们已经说过,本篇文章只解释区块链的狭义上的意义。维基百科中这样解释区块链:
区块链是借由密码学串接并保护内容的串连交易记录(又称区块)。每一个区块包含了前一个区块的加密散列、相应时间戳记以及交易数据(通常用默克尔树算法计算的散列值表示)[7],这样的设计使得区块内容具有难以篡改的特性。用区块链所串接的分布式账本能让两方有效纪录交易,且可永久查验此交易。
几乎所有区块链项目本质上都是为了记录和确认交易(transaction)。而这种记录和确认是通过区块进行的。也就是说,矿工对一些交易进行合法性检查后,使用区块的形式将其打包,从而产生了一个新的区块数据。
在每个区块中,都会有一个字段记录自己父区块的哈希。正是这个父区块的哈希,将区块组成了类似数据结构中的单向列表结构,也被称之为“链”。
这就是区块链的含义。一般人们会说使用父区块哈希组成链的方式可以防止区块被篡改,因为如果修改了某个区块,它的哈希就发生了改变,导致与子区块中记录的哈希不符,从而使这种修改不被承认。但我个人觉得在区块链技术火爆之前就已经存在防篡改的技术(比如数字签名),这些技术完全可以应用到区块的保护上来。因此我认为将区块组织成链的形式虽然有防篡改的意义,但未必是主要目的。组成链的好处是可以更方便的处理出现分支(即分叉)的情况。试想如果使用数组的形式组织区块,如果出现分支处理起来肯定不如链表方便。
区块的组织
区块如何组成链
我们先整体地看一下在以太坊中区块是如何组织成链的。然后再深入细节,去讨论一些具体的问题。
在以太坊中,区块可能会组织成下面这个样子: 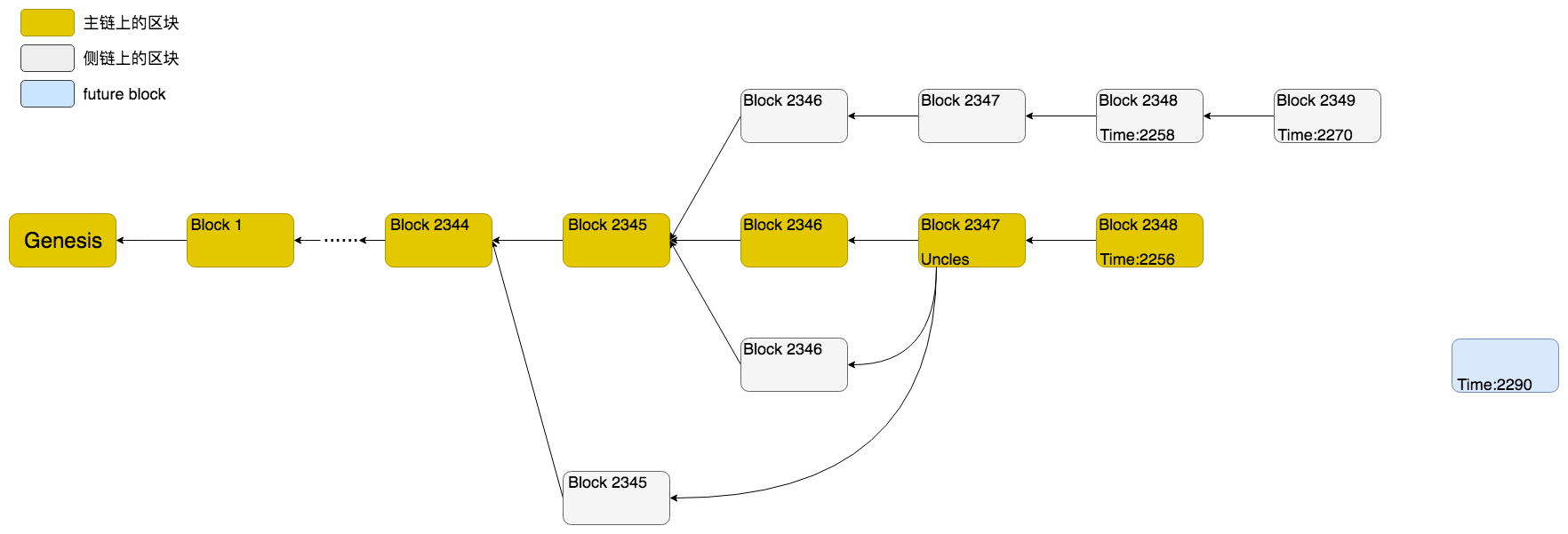
这个图体现了以太坊区块链的大多数特性。大多数区块组成了一个链条,每个区块指向了自己的父多块,直到创世区块(Genesis)。但也很容易注意到,这个链条从头到尾并不是只有一条,而是有不少“毛刺”似的或长或短的分支链。这些分支链条被称为 侧链,而主要的那个链条则是 主链,而这种出现分支链的情况就叫做 分叉。
每个区块都会有一个 高度,它是这个区块在链条上的位置的计数。比如创世块的高度是0,因为它是第一个区块。第二个区块的高度是1,以此类推。如果我们仔细观察图中的区块高度,会发现主链上最后一个区块的高度并不是最大。这说明以太坊中并不以区块高度来判断是主链还是侧链。后面我们会再详细说一下这个问题。
不管是主链还是侧链上,都有一些侧链上的区块又被“包含”回来的情况,也就是说有些区块不仅会指向父块,还可能指向自己的叔叔辈的区块。这是以太坊中比较有特色的特点,叫做 叔块,名字也是非常形象。
还有一些区块不在链上,这些区块被称为 future block。以太坊有时候会收到一些时间戳较父块大得太多的区块,因此会作为”future block”暂存这些区块。待到时机成熟时再尝试将其加入到链中。
另外关于修剪的内容没能在这个图上体现出来。以太坊的state存储了所有以太坊的账户信息,state底层使用trie对象存储。由于trie的机制和以太坊日益增长的数据,存储全部state数据需要非常大的磁盘空间。因此以太坊的区块增加了“修剪”state的功能,即那些比较旧的区块的state是不存储的,只存储比较新的区块的state。我们后面还会详细分析这块功能。
这就是以太坊中区块的组织形式。可以看到,以太坊中的区块链不仅仅是简单的一个链条,它还加上了一些其它的功能和特性。
区块的完整数据
看完了“链”,我们再来看看“区块”。一个完整的区块都包含哪些数据呢?
我们首先看一下代表区块的结构体Block,它定义在core/types/block.go文件中:
type Block struct {
header *Header //区块头
uncles []*Header //当前块所包含的叔块
transactions Transactions //当前块所包含的所有交易
......
}
//下面的字段解释以ethash共识为准。在clique共识中字段的意义不尽相同,这里不作讨论。
//感兴趣的读者可以参看对clique的介绍:https://yangzhe.me/2019/02/01/ethereum-clique/
type Header struct {
ParentHash common.Hash //父区块的哈希
UncleHash common.Hash //所有叔块的哈希(Block.uncles)
Coinbase common.Address //接受出块奖励的地址。矿工出块时在这个字段填入自己的地址。
Root common.Hash //此区块包含的所有交易完成后,state对象的哈希值
TxHash common.Hash //此区块包含的所有交易的哈希(Block.transactions)
ReceiptHash common.Hash //此区块所有交易完成后所产生的所有收据的哈希
Bloom Bloom //布隆过滤对象,用来查找交易产生的Log
Difficulty *big.Int //此区块的难度值
Number *big.Int //此区块的高度
GasLimit uint64 //此区块所有交易消耗的gas值的上限
GasUsed uint64 //此区块所有交易消耗的gas的实际值
Time *big.Int //区块时间戳
Extra []byte //区块的额外数据
MixDigest common.Hash //以太坊hashimoto算法产生的哈希。详细可参看对ethash的介绍:https://yangzhe.me/2019/02/14/ethereum-ethash-theory/
Nonce BlockNonce //PoW共识挖矿时通过随意此字段,使区块哈希发生变化从而产生符合Difficulty值要求的区块哈希
}
上面Block结构体中只列出了比较重要的字段,其它字段其实并不存储在数据库中,而是作为缓存数据存在。Header结构体存储了大多数的主要数据。所有结构体的字段的意义已在注释中注明,这里不再解释。
需要稍微说明一下的是,Block结构中的uncles和transactions数据是作为Body这个结构体和概念存储的。也就是说,一个区块在数据库中被分为Header和Body两部分。
上面这些结构体作为组成区块的主体,当然是区块中必不可少数据。除了这些数据以外,在实际存储区块链时,还有其它数据也会进行存储:
- 当前区块的Total Difficulty(Td)
这个数据记录了从创世区块到当前区块中,所有区块的Difficulty值的累加值。比如区块0(创世区块)的Difficulty为1,区块1的Difficulty为2,那么区块1的Total Difficulty就是3。 - receipts
即当前区块的所有交易执行完成后产生的所有收据数据。 - txlookupentries
这是一个辅助结构体,用来通过交易哈希查询交易属于哪个区块。因为交易数据是作为区块的一部分一起存储的,所以想要单独查找某一笔交易,需要先知道这笔交易在哪个区块中。 - state
state存储了以太坊所有账户的信息。在生成区块时会确认很多的交易,因此多数情况下每个区块所对应的state是不同的。在区块的头部,Header.Root记录了区块对应的state的哈希。而数据库中也会存储state的相关数据(关于state我们以后的文章会进行详细的介绍)。 - Preimages
数据库中还会存储一种值叫preimages,这是trie中的一种概念和数据,preimages其实是secureTrie中hashkey到realkey的映射。这个数据并不重要,因此我们就不作过多讨论了。
主链与侧链
在以太坊的代码里,有主链(chain)和侧链(side chain)之分。主链就是被承认的链,后续的新产生的区块以主链的最后一个区块为父区块。侧链就是未被承认的链,它有可能继续增长,也有可能就此停止。如果继续增长,它的Td值有可能超过主链从而变成了主链,这时原来的主链反而成了侧链。
以前没有仔细的去琢磨区块链的实现,我以为这些区块链项目就只有一条链,就是主链。所有区块在主链上一个一个的增加。这是一种理想的情况,现实是,区块链项目是一个分布式的项目,且节点之前彼此是不信任的。假如节点A和B生成了一个高度相同的区块,并且它们分别将这个消息告诉了其它的节点。那么有的节点将A的区块加入了链中,有的节点将B的区块加入了链中。这种情况就产生了分叉。如果只有一个主链,节点之间互不承认其它的分支,那么这个分叉就永远继续下去了。这显然是不行的。
因此在以太坊中,主链和侧链是同时存在于数据库中的。每加入一个新的区块,就是重新判断新加入的区块所在的分支是否变成了主链。如果变成了主链,就需要进行调整,把新加入区块所在的分支变成主链,同时取消原来的主链。
如何判断是否主链
新插入区块时会判断当前区块所在的分支是否已经成为主链了。判断的代码在BlockChain.writeBlockWithState中:
func (bc *BlockChain) writeBlockWithState(block *types.Block, receipts []*types.Receipt, state *state.StateDB) (status WriteStatus, err error) {
ptd := bc.GetTd(block.ParentHash(), block.NumberU64()-1)
currentBlock := bc.CurrentBlock()
//localTd是主链上最新的一个区块的累计Difficulty值(Total Difficulty)
localTd := bc.GetTd(currentBlock.Hash(), currentBlock.NumberU64())
externTd := new(big.Int).Add(block.Difficulty(), ptd)
......
reorg := externTd.Cmp(localTd) > 0
currentBlock = bc.CurrentBlock()
if !reorg && externTd.Cmp(localTd) == 0 {
//处理新加入的区块的TotalDifficulty与主链的TotalDifficulty相等的情况
if block.NumberU64() < currentBlock.NumberU64() {
//如果新加入的区块的高度较小,则调整主链
reorg = true
} else if block.NumberU64() == currentBlock.NumberU64() {
//如果高度相同,则求助于shouldPreserve函数。这个函数虽然是外部传入的,但整个以太坊代码中
//只有Ethereum.shouldPreserve这一个定义。其基本想法是如果是矿工自己产生的块则返回true,
//否则返回false。
var currentPreserve, blockPreserve bool
if bc.shouldPreserve != nil {
currentPreserve, blockPreserve = bc.shouldPreserve(currentBlock), bc.shouldPreserve(block)
}
//如果不保留currentBlock且保留新加入的block,则进行调整
//如果不保留currentBlock也不保留新加入的block,通过使用随机数仍有一半的机会调整
reorg = !currentPreserve && (blockPreserve || mrand.Float64() < 0.5)
}
}
if reorg {
// Reorganise the chain if the parent is not the head block
//如果决定调整,还要看新加入的区块的父区块是否就是主链上的最新区块。如果是就不必调整了。
if block.ParentHash() != currentBlock.Hash() {
if err := bc.reorg(currentBlock, block); err != nil {
return NonStatTy, err
}
......
status = CanonStatTy
}
}
......
// Set new head.
if status == CanonStatTy {
bc.insert(block) //BlockChain.insert会将block作为主链上的区块写入相关数据
}
}
上面这段代码就是在判断是否需要调整主链,如果是则调用BlockChain.reorg调整。判断的逻辑可以概括如下:
- 当前区块的Td值
externTd是否大于当前主链区块的Td值localTd。如果大于则进行调整 - 如果Td值相同,则高度小的被当成主链
- 如果高度也相同,两个分支上的最新区块哪个是自己产生的;自己产生的区块所在分支被作为主链
- 如果没有自己产生的区块,就通过随机数来“抛硬币”了(mrand.Float64() < 0.5)
- 在真正调整之前,还要再判断一下新加入的区块是否就在当前主链上,如果就不用再调整啦
需要说明一下的是,整个BlockChain.writeBlockWithState的前面的代码都没有将block变量作为主链上的区块写入的逻辑,包括BlockChain.reorg也只是调整block的所有父区块,并不包括block自己。直到最后if status == CanonStatTy这个判断,才调用BlockChain.insert将block写成主链上的区块。
如何调整成为主链
知道了主链的判断逻辑,下面我们来看看调整的逻辑。调整主要通过BlockChain.reorg和BlockChain.insert实现的:
func (bc *BlockChain) reorg(oldBlock, newBlock *types.Block) error {
var (
newChain types.Blocks
oldChain types.Blocks
commonBlock *types.Block
deletedTxs types.Transactions
)
//这里if/else和紧跟着的for的功能是查找oldBlock和newBlock两个分支的共同祖先commonBlock,
//并将达到共同祖先的路径上所有区块各自记录在newChain和oldChain中。同时将oldBlock的分支
//上的所有transaction放到deletedTxs中。
if oldBlock.NumberU64() > newBlock.NumberU64() {
......
} else {
......
}
for {
......
}
//调用BlockChain.insert将newBlock分支上所有区块作为主链区块写入数据库中
//同时删掉只在旧链上的交易的索引信息(并不删除交易本身,只是删除 txLookupEntry)
var addedTxs types.Transactions
for i := len(newChain) - 1; i >= 0; i-- {
bc.insert(newChain[i])
rawdb.WriteTxLookupEntries(bc.db, newChain[i])
addedTxs = append(addedTxs, newChain[i].Transactions()...)
}
diff := types.TxDifference(deletedTxs, addedTxs)
for _, tx := range diff {
rawdb.DeleteTxLookupEntry(batch, tx.Hash())
}
}
BlockChain.reorg的主要逻辑就是查找两个分支的共同祖先,然后将新分支上至共同祖先的所有区块写成主链上的区块,这一工作主要由BlockChain.insert完成的:
func (bc *BlockChain) insert(block *types.Block) {
// If the block is on a side chain or an unknown one, force other heads onto it too
updateHeads := rawdb.ReadCanonicalHash(bc.db, block.NumberU64()) != block.Hash()
// Add the block to the canonical chain number scheme and mark as the head
rawdb.WriteCanonicalHash(bc.db, block.Hash(), block.NumberU64())
rawdb.WriteHeadBlockHash(bc.db, block.Hash())
bc.currentBlock.Store(block)
// If the block is better than our head or is on a different chain, force update heads
if updateHeads {
bc.hc.SetCurrentHeader(block.Header())
rawdb.WriteHeadFastBlockHash(bc.db, block.Hash())
bc.currentFastBlock.Store(block)
}
}
将区块写为主链的方法其实非常简单,就是在数据库中建立一个区块高度到区块哈希的映射。当我们仅使用区块高度获取一个区块时,获取的就是主链上的区块;同时主链会有一个标记,记录着主链上的最新区块的哈希。
BlockChain.insert主要就是操作数据库。这里我们比较关注第二块代码,rawdb.WriteCanonicalHash函数将在数据库中创建一个区块高度到区块哈希的映射,rawdb.WriteHeadBlockHash函数将当前区块在数据库中标记为“最新的区块”。由此确认了参数block所代表的区块的主链地位。
genesis
genesis这个单词在区块链项目中有其特定的含义,一般都是指“创世块”。在以太坊中,创世块的数据在配置文件中;如果配置文件中没有,则使用代码中的默认数据。
如果你使用puppeth程序生成一个私链的配置文件,里面就是genesis数据。
如果你直接运行geth程序,那么使用的就是代码中默认的genesis数据:
func DefaultGenesisBlock() *Genesis {
return &Genesis{
Config: params.MainnetChainConfig,
Nonce: 66,
ExtraData: hexutil.MustDecode("0x11bbe8db4e347b4e8c937c1c8370e4b5ed33adb3db69cbdb7a38e1e50b1b82fa"),
GasLimit: 5000,
Difficulty: big.NewInt(17179869184),
Alloc: decodePrealloc(mainnetAllocData),
}
}
在程序启动时,geth会调有SetupGenesisBlockWithOverride函数将genesis区块写入数据库中。在这个函数的注释中,详细解释了它处理的几种情况。这里我们只关注数据库中没有创世块,也即第一次初始化的情况:
func SetupGenesisBlockWithOverride(db ethdb.Database, genesis *Genesis, constantinopleOverride *big.Int) (*params.ChainConfig, common.Hash, error) {
......
stored := rawdb.ReadCanonicalHash(db, 0)
if (stored == common.Hash{}) {
if genesis == nil {
log.Info("Writing default main-net genesis block")
genesis = DefaultGenesisBlock()
} else {
log.Info("Writing custom genesis block")
}
block, err := genesis.Commit(db)
return genesis.Config, block.Hash(), err
}
......
}
参数genesis变量代表的是配置文件中的创世块信息,如果为空则使用默认的数据(DefaultGenesisBlock)。而后调用Commit方法将其写入数据库中。
pruned block
以太坊运行以来,随着时间的推移,以太坊的客户端需要存储的数据越来越多,多到了难以接受的地步。下面是网络上关于以太坊数据增长的一张图: 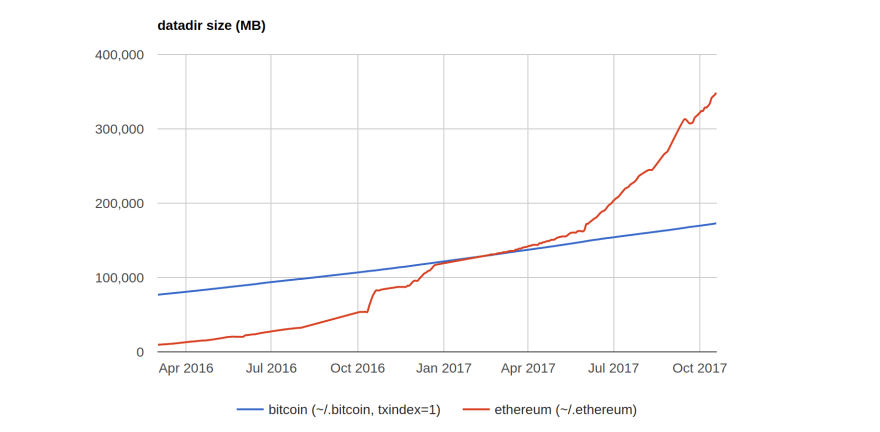
可以看到在17年10月的时候,以太坊的数据已经达大于300G,且数据线的走势是一个指数增长的形势,照这种情况发展下去,很快就超过1T了,这么大的数据量对于一普通用户是难以接受的。
以太坊的团队通过对区块数据进行修剪的方式来解决这个问题。准确的说,修剪的其实是state数据,因为导致以太坊数据增长如此之快的最终原因不是区块数量的增长,而是state数据的增长。那么为什么state的数据量会增长的如此之快呢?这要从state的实现方式说起。
state的实现方式
以太坊的state对象是以太坊账户数据的“状态机”,记录着每一个区块下所有账户的相关信息。而state对象的底层实现是trie(关于trie的详细介绍可以参看这里)。trie同时拥有默克尔树和字典树的功能,但本质上,trie就是一棵树,且trie的key就是以太坊的账户地址,而value而是账户地址对应的信息,也就是说账户地址的信息存储在树的叶子结节中。因此如果一个账户信息发生了改变,那么所有这个叶子到根结点这个路径上的结点都会发生改变,如下图所示: 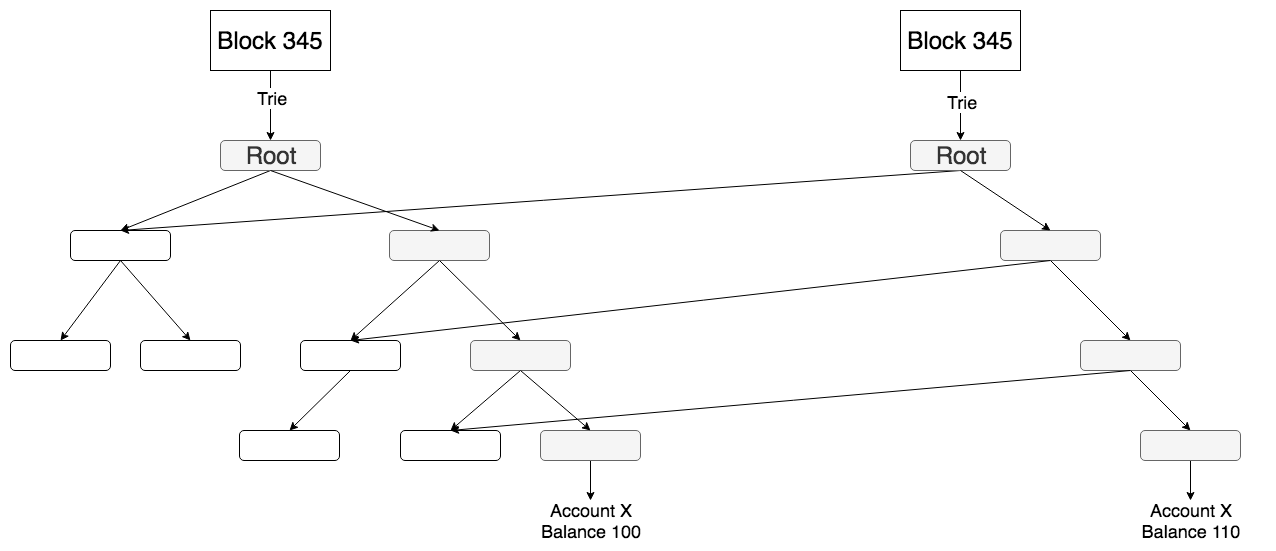
如果使用上图举例,为了存储一个Account X的修改,需要总共存储4个新的节点(实际可能不止4个)。可想而知数据增长的速度。
修剪
那么一个以太坊节点有没有必要存储state的所有历史数据呢?绝大多数情况下是不需要的。对于那些不需要的数据,我们可以不进行存储。万一哪天需要用到了,由于保存了完整的区块信息,我们是可以费点时间重新计算得到这些数据的。
以太坊提供的方式是对trie树的节点进行修剪。在trie的实现中,会对存在于内存中的节点进行“引用计数”,即每个节点都有一个记录自己被引用次数的数字,当引用数量变为0时,节点内存就会被释放,也就不会被写入到数据库中去了。trie模块提供了trie.Database.Reference和trie.Database.Dereference方法,可以引用和解引用某一个节点(关于对trie节点的引用,可以参考这篇文章和这篇文章)。
trie节点的这种“引用计数”式的设计应该是很好理解的,这篇文章也对其进行了详细的说明。在本篇文章里,我们重点关注blockchain模块是如何使用这一功能对state进行修剪的。
对state进行修剪是在插入区块时进行的,具体是在BlockChain.writeBlockWithState中,由于代码较长,我们将其分开一点点进行讨论。
func (bc *BlockChain) writeBlockWithState(block *types.Block, receipts []*types.Receipt, state *state.StateDB) (status WriteStatus, err error) {
......
root, err := state.Commit(bc.chainConfig.IsEIP158(block.Number()))
if err != nil {
return NonStatTy, err
}
triedb := bc.stateCache.TrieDB()
// If we're running an archive node, always flush
if bc.cacheConfig.Disabled {
if err := triedb.Commit(root, false); err != nil {
return NonStatTy, err
}
} else {
......
}
......
}
在BlockChain.writeBlockWithState前半部分的代码中,主要是写入区块数据和Td(TotalDifficulty)。然后调用state.Commit将区块的state对象提交到数据库中。注意这个地方是有些令人迷惑的。前面我们说过修剪针对的是trie对象的内存中的节点,而非已写入数据库中的节点。既然已经调用state.Commit写入数据库了,还怎么进行修剪呢?其实trie模块自己实现了一个数据库对象,也就是下一条语句triedb = bc.stateCache.TrieDB()中的triedb。这个数据库对象是有缓存的,并不会直接将节点数据真正写入数据库中。
然后这段代码对cacheConfig.Disabled进行了判断,看是否是”archive node”。这一配置主要由配置文件中的NoPruning字段进行配置。如果设置为true则不进行修剪,直接调用triedb.Commit将数据提交到数据库中。这时数据真的被写入数据库了。否则就进行修剪进程。也就是else部分的代码:
func (bc *BlockChain) writeBlockWithState(block *types.Block, receipts []*types.Receipt, state *state.StateDB) (status WriteStatus, err error) {
if bc.cacheConfig.Disabled {
......
} else {
// Full but not archive node, do proper garbage collection
triedb.Reference(root, common.Hash{}) // metadata reference to keep trie alive
bc.triegc.Push(root, -int64(block.NumberU64()))
if current := block.NumberU64(); current > triesInMemory {
......
// Find the next state trie we need to commit
header := bc.GetHeaderByNumber(current - triesInMemory)
chosen := header.Number.Uint64()
......
// Garbage collect anything below our required write retention
for !bc.triegc.Empty() {
root, number := bc.triegc.Pop()
if uint64(-number) > chosen {
bc.triegc.Push(root, number)
break
}
triedb.Dereference(root.(common.Hash))
}
}
}
}
进行修剪之前,首先会引用这个新的trie树的根节点,因为毕竟是当前区块产生了这个新的trie树,而目前我们还不知道是否会丢弃这棵树。
在进行引用之后,则将root和区块的高度写入BlockChain的triegc字段中。这里我们必须介绍一下bc.triegc这个字段。triegc代表的是trie的回收队列(trie Garbage Collect),它的类型是一个优先级队列。从上面的代码中可以看到主要用到了Push和Pop两个方法。其中Push将数据写入队列中,附带着一个优先级值(第二个参数)。而Pop则将当前队列中优先级值最大的数据弹出队列并返回。由于Push时优先级值是区块高度的相反数,是一个负数,因此Pop时首先弹出的是高度最小的区块的数据(也即最老旧的区块)。
在操作完成triegc后,会对当前区块高度进行判断,只有高度大于triesInMemory(其值在代码中定义为128),才进行修剪。这是因为后面的逻辑不会对最新的triesInMemory个区块进行修剪。
这里为了讲述方便,我们先来看一下if判断里最后一段代码。在进行一番处理后,将通过一个for循环对triegc中存储的trie进行真正的修剪,即解引用triegc中记录的trie树的所有节点。在这一过程中,如果某一个trie树的节点的引用计数变为0,就会被丢弃,不会写入数据库中。这一过程一直持续到triegc为空,或最老旧的区块高度也大于值chosen。如果区块高度大于chosen,则将数据重新放到triegc中,留待以后处理。
那么chosen是怎么来的呢?很简单,它实际上就是当前区块向前减triesInMemory(128)的区块高度。结合for循环里的代码,我们可以发现,对于最新的(或者说高度最高的)128个区块,是不会进行修剪的。它们会被重新放回triegc中。随着区块高度的增加,当它们不再是那最新的128个区块之一时,再对它们进行修剪。
下面我们来看看if判断是被省略的其它代码:
func (bc *BlockChain) writeBlockWithState(block *types.Block, receipts []*types.Receipt, state *state.StateDB) (status WriteStatus, err error) {
......
if current := block.NumberU64(); current > triesInMemory {
// If we exceeded our memory allowance, flush matured singleton nodes to disk
var (
nodes, imgs = triedb.Size()
limit = common.StorageSize(bc.cacheConfig.TrieDirtyLimit) * 1024 * 1024
)
if nodes > limit || imgs > 4*1024*1024 {
triedb.Cap(limit - ethdb.IdealBatchSize)
}
// Find the next state trie we need to commit
header := bc.GetHeaderByNumber(current - triesInMemory)
chosen := header.Number.Uint64()
// If we exceeded out time allowance, flush an entire trie to disk
if bc.gcproc > bc.cacheConfig.TrieTimeLimit {
......
}
......
}
......
}
这段代码有两个功能。一个是检查triedb中的缓存大小,如果超过某个值则调用triedb.Cap将缓存大小调整为适当值。triedb.Cap会将缓存中的一些trie树写入数据库中,直接缓存大小达到限定值。因此在这一过程中有可能会把一些以后会被修剪掉的节点写入到数据库中。
第二个功能就是chosen变量的值的计算。前面我们已经说了,不再赘述。
这段代码中还有一段被忽略的if判断和处理,我们单独看一下:
func (bc *BlockChain) writeBlockWithState(block *types.Block, receipts []*types.Receipt, state *state.StateDB) (status WriteStatus, err error) {
......
if bc.gcproc > bc.cacheConfig.TrieTimeLimit {
// If we're exceeding limits but haven't reached a large enough memory gap,
// warn the user that the system is becoming unstable.
if chosen < lastWrite+triesInMemory && bc.gcproc >= 2*bc.cacheConfig.TrieTimeLimit {
log.Info("State in memory for too long, committing", ......)
}
// Flush an entire trie and restart the counters
triedb.Commit(header.Root, true)
lastWrite = chosen
bc.gcproc = 0
}
......
}
这里又出来一个变量bc.gcproc,它是BlockChain的一个字段,其类型是time.Duration。这个字段代表的是调用BlockChain.insertChain插入区块时,从上一个被插入到主链上的未被修剪的区块到当前区块,计算完整state所花费的累计时间。当这个累计时间超过bc.cacheConfig.TrieTimeLimit时,当前的state也不会被修剪,直接写入数据库中。也就是说,每隔一些区块(计算这区块的state的累计时间超过了bc.cacheConfig.TrieTimeLimit),state就会被直接写入数据库而不被修剪。
下面列出了gcproc值被修改时代码,通过这段代码相信可以更好的理解“从上一个被插入到主链上的未被修剪的区块到当前区块,所计算完整state所花费的累计时间”这句话(代码经过精简):
func (bc *BlockChain) insertChain(chain types.Blocks, verifySeals bool) (int, []interface{}, []*types.Log, error) {
......
for ; block != nil && err == nil; block, err = it.next() {
......
start := time.Now()
state, err := state.New(parent.Root(), bc.stateCache)
receipts, logs, usedGas, err := bc.processor.Process(block, state, bc.vmConfig)
bc.Validator().ValidateState(block, parent, state, receipts, usedGas)
proctime := time.Since(start)
status, err := bc.writeBlockWithState(block, receipts, state)
switch status {
case CanonStatTy:
// 如果区块被加入到了主链中,则将计算state的时候累加到bc.gcproc中
bc.gcproc += proctime
......
}
}
......
}
这样做的目的是可以将重新生成任一被修剪的区块的state的时间限制在一定范围内。假如以后需要重新计算某一区块的state时,只需要找到最近的一个未被修剪的祖先区块,从这个祖先区块开始算起。而这个计算时间基本上在bc.cacheConfig.TrieTimeLimit以内。
现在我们对state的修剪进行一个总结:
- 高度最高的triesInMemory(128)个区块暂时也不会被修剪;但随着高度的增长不再属于此范围内的区块时,仍可能会被修剪
- 修剪的方法是在trie内部通过引用计数引用所有缓存中的树节点,当引用计算为0时节点将被删除。
- 修剪时限制
trie.Database中缓存占用内存大小。 - 修剪时限制修剪后重新生成state的时间。
FutureBlocks
在以太坊中还有一类区块被称为”FutureBlocks”,即“未来的区块”。这些区块被存储在BlockChain.futureBlocks字段中,通过在代码中查看这个字段的使用情况,发现只有方法BlockChain.addFutureBlock才会写入这个字段;再查找这个方法的调用情况,我们发现有三处调用都在BlockChain.insertChain中:
func (bc *BlockChain) insertChain(chain types.Blocks, verifySeals bool) (int, []interface{}, []*types.Log, error) {
......
//参数chain[0]在被验证的时候返回ErrFutureBlock,或都chain[0]被验的时候返回ErrUnknownAncestor(找不到父区块)但父区块其实在futureBlocks中
case err == consensus.ErrFutureBlock || (err == consensus.ErrUnknownAncestor && bc.futureBlocks.Contains(it.first().ParentHash())):
//block变量的初始值其实就是chain[0]。for的判断逻辑是:第一个区块(即chain[0])上面的case已经判断过了,因此可以直接加入futureBlocks中;由于前面的区块被加入到了futureBlocks而不是数据库中,因而后面的区块在验的时候应该是找不着父区块的,所以也当作futureBlocks处理。
for block != nil && (it.index == 0 || err == consensus.ErrUnknownAncestor) {
if err := bc.addFutureBlock(block); err != nil {
return it.index, events, coalescedLogs, err
}
block, err = it.next()
}
//将验证正常区块加入到数据库中
......
//上面验证后可能还有一些未能加入的区块,这里再次判断是否是将其加入futureBlocks。
//判断逻辑与上面相同
if block != nil && err == consensus.ErrFutureBlock {
if err := bc.addFutureBlock(block); err != nil {
return it.index, events, coalescedLogs, err
}
block, err = it.next()
for ; block != nil && err == consensus.ErrUnknownAncestor; block, err = it.next() {
if err := bc.addFutureBlock(block); err != nil {
return it.index, events, coalescedLogs, err
}
stats.queued++
}
}
}
从这段代码中可以看出,当插入一组区块时,如果前一个区块在被验证时返回consensus.ErrFutureBlock,那么它后续的区块也几乎会被当成futureBlock对待。那么哪里会返回这个错误呢?由于验证的代码位于共识模块中,因此这个错误在ethash和clique中返回的:
func (c *Clique) verifyHeader(chain consensus.ChainReader, header *types.Header, parents []*types.Header) error {
......
if header.Time.Cmp(big.NewInt(time.Now().Unix())) > 0 {
return consensus.ErrFutureBlock
}
......
}
func (ethash *Ethash) verifyHeader(chain consensus.ChainReader, header, parent *types.Header, uncle bool, seal bool) error {
......
if uncle {
......
} else {
if header.Time.Cmp(big.NewInt(time.Now().Add(allowedFutureBlockTime).Unix())) > 0 {
return consensus.ErrFutureBlock
}
}
......
}
从这段代码我们也可以看出,在ethash中如果不包含uncle,那么区块的时间戳大于当前时间allowedFutureBlockTime(15秒)会被认为是futureBlock;而clique中只要区块的时间戳比当前时间大,就认为是futureBlock。
需要稍微提一下的是,在BlockChain.addFutureBlock中也有一个条件判断:
func (bc *BlockChain) addFutureBlock(block *types.Block) error {
max := big.NewInt(time.Now().Unix() + maxTimeFutureBlocks)
if block.Time().Cmp(max) > 0 {
return fmt.Errorf("future block timestamp %v > allowed %v", block.Time(), max)
}
bc.futureBlocks.Add(block.Hash(), block)
return nil
}
如果区块的时间戳大于当前时间maxTimeFutureBlocks(30秒)就会被直接丢弃,而不会加入到BlockChain.futureBlocks中。
到此我们对成为一个futureBlock的条件作一个总结。首先明确一个前提是进行条件判断的时候是在插入一组区块(chain)的时候。满足以下任意一条,都会被调用BlockChain.addFutureBlock方法:
- 某区块被共识代码判断为
ErrFutureBlock(ethash中区块时间戳大于当前时间15秒, clique区块时间戳中大于当前时间) - 同一组区块(chain)中,前面有一个区块被判断为futureBlock,随后的所有找不到父区块的区块都会被判断为futureBlock
- 找不到某区块的父块但父块在
BlockChain.futureBlocks中
要注意的调用BlockChain.addFutureBlock后,还有一个判断条件,即区块时间戳大于当前时间30秒的话,则不会被加入到BlockChain.futureBlocks字段中。
还有一个需要注意的点是,在创建BlockChain时会创建一个线程BlockChain.update,此线程每隔5秒钟调用BlockChain.procFutureBlocks,尝试将BlockChain.futureBlocks中的区块加入到数据库中。代码比较简单,就不再详细说明了。
插入与验证
前面我们主要讲了以太坊区块链中的一些概念和细节,现在我们详细看一下区块是如何被加入到链中的。在以太坊的区块链代码中,插入区块的方法是BlockChain.InsertChain,但主要的代码是由BlockChain.insertChain完成的。由于逻辑比较多且稍复杂,我们分阶段来分析具体的代码。
BlockChain.InsertChain方法的代码比较简单短,我们直接完整的拷贝到这里:
func (bc *BlockChain) InsertChain(chain types.Blocks) (int, error) {
// Sanity check that we have something meaningful to import
if len(chain) == 0 {
return 0, nil
}
// Do a sanity check that the provided chain is actually ordered and linked
for i := 1; i < len(chain); i++ {
if chain[i].NumberU64() != chain[i-1].NumberU64()+1 || chain[i].ParentHash() != chain[i-1].Hash() {
// Chain broke ancestry, log a message (programming error) and skip insertion
log.Error("Non contiguous block insert", "number", ......)
return 0, fmt.Errorf("non contiguous insert: ......", ......)
}
}
// Pre-checks passed, start the full block imports
bc.wg.Add(1)
bc.chainmu.Lock()
n, events, logs, err := bc.insertChain(chain, true)
bc.chainmu.Unlock()
bc.wg.Done()
bc.PostChainEvents(events, logs)
return n, err
}
这里首先进行了两个简单的检查,一是检查参数chain的长度是否为0,二是检查chain中的各区块的高度是否是从小到大按顺序依次排列的。检查完成后,就调用BlockChain.insertChain进行实际的插入工作。插入完成后会返回一些通知事件,因此调用BlockChain.PostChainEvents发送这些通知事件。
然后我们看一下BlockChain.insertChain第一阶段的代码:
func (bc *BlockChain) insertChain(chain types.Blocks, verifySeals bool) (int, []interface{}, []*types.Log, error) {
......
for i, block := range chain {
headers[i] = block.Header()
seals[i] = verifySeals
}
abort, results := bc.engine.VerifyHeaders(bc, headers, seals)
defer close(abort)
// Peek the error for the first block to decide the directing import logic
it := newInsertIterator(chain, results, bc.Validator())
......
}
方法一开始最重要的是调用engine.VerifyHeaders对所有区块的头部进行验证(其中bc.engine是共识接口)。注意这个方法的实现是异步的,它会返回一个channel用来获取验证的结果,也即变量results。这里的代码使用newInsertIterator和results创建一个迭代器,后面使用这个迭代器来获取每一个验证结果。
我们继续看下一阶段的代码:
func (bc *BlockChain) insertChain(chain types.Blocks, verifySeals bool) (int, []interface{}, []*types.Log, error) {
......
block, err := it.next()
switch {
// First block is pruned, insert as sidechain and reorg only if TD grows enough
case err == consensus.ErrPrunedAncestor:
return bc.insertSidechain(it)
// First block is future, shove it (and all children) to the future queue (unknown ancestor)
case err == consensus.ErrFutureBlock || (err == consensus.ErrUnknownAncestor && bc.futureBlocks.Contains(it.first().ParentHash())):
for block != nil && (it.index == 0 || err == consensus.ErrUnknownAncestor) {
if err := bc.addFutureBlock(block); err != nil {
return it.index, events, coalescedLogs, err
}
block, err = it.next()
}
// If there are any still remaining, mark as ignored
return it.index, events, coalescedLogs, err
case err == ErrKnownBlock:
// Skip all known blocks that behind us
current := bc.CurrentBlock().NumberU64()
for block != nil && err == ErrKnownBlock && current >= block.NumberU64() {
stats.ignored++
block, err = it.next()
}
case err != nil:
stats.ignored += len(it.chain)
bc.reportBlock(block, nil, err)
return it.index, events, coalescedLogs, err
}
......
}
这段代码虽然稍长但逻辑很简单,就是一个switch/case处理被插入的第一个区块的验证结果。我们分情况进行说明:
- case1: 第一个区块是被“修剪”的区块
前面我们讲过,所谓被“修剪的区块”,就是指区块虽然存在,但它的state对象却不存在。代码中的处理是将整个chain作为侧链插入。因为根据修剪的规则,主链上的最新的区块(triesInMemory)是不可能不存在state对象的,但chain[0]的父块不存在state对象,说明它的父块不可能是主链上的最新的块,那么整个的chain参数所代表的这组区块肯定是在其它分支链上了。 - case2: 第一个区块是futureBlock
futureBlock的概念前面我们也讲过。这里的判断逻辑是,要么chain[0]的验证结果是ErrFutureBlock,要么是找不到父区块(ErrUnknownAncestor)但父区块存在于futureBlocks中。相应的处理逻辑是将第一个区块及后续找不到父区块的区块全当成futureBlock,调用addFutureBlock。然后就直接返回了。 - case3: 第一个区块已经完整存在于数据库中
注意这里说的完整存在不仅是指区块数据,也包括state对象的数据。既然区块已经完整存在了,那么就没必须再处理一遍了。因此这里的处理方式就是忽略所有已以完整存在的区块。 - case4: 其它未知错误
如果有其它未知错误,只能直接从方法只返回啦。
处理完第一个区块的错误信息,我们继续看后续的代码:
func (bc *BlockChain) insertChain(chain types.Blocks, verifySeals bool) (int, []interface{}, []*types.Log, error) {
......
//for循环太长,这里只保留了重要代码,并去掉了一些错误处理代码
for ; block != nil && err == nil; block, err = it.next() {
parent := it.previous()
if parent == nil {
parent = bc.GetBlock(block.ParentHash(), block.NumberU64()-1)
}
state, err := state.New(parent.Root(), bc.stateCache)
// Process block using the parent state as reference point.
receipts, logs, usedGas, err := bc.processor.Process(block, state, bc.vmConfig)
// Validate the state using the default validator
bc.Validator().ValidateState(block, parent, state, receipts, usedGas)
// Write the block to the chain and get the status.
status, err := bc.writeBlockWithState(block, receipts, state)
switch status {
case CanonStatTy:
coalescedLogs = append(coalescedLogs, logs...)
events = append(events, ChainEvent{block, block.Hash(), logs})
lastCanon = block
// Only count canonical blocks for GC processing time
bc.gcproc += proctime
case SideStatTy:
events = a ppend(events, ChainSideEvent{block})
}
}
......
}
这一段代码就是一个for循环,不断处理所有验证通过的区块。代码虽然较多,但逻辑还是比较简单的,就是调用processor.Process生成区块对应的state对象和收据(receipt),并对state对象进行验证(ValidateState)。如果全都正常,则调用writeBlockWithState将区块、state对象和收据全部写入数据库中。writeBlockWithState在将区块写入数据库后,可能会调用reorg对主链与侧链进行调整。随后代码跟据返回值status变量可以判断此区块是被写入主链了(CanonStatTy)还是写入侧链了(SideStatTy)。如果写入主链,则生成一个ChainEvent事件;如果写入侧链则生成一个ChainSideEvent事件。
下面我们看看insertChain中最后一段代码:
func (bc *BlockChain) insertChain(chain types.Blocks, verifySeals bool) (int, []interface{}, []*types.Log, error) {
......
if block != nil && err == consensus.ErrFutureBlock {
if err := bc.addFutureBlock(block); err != nil {
return it.index, events, coalescedLogs, err
}
block, err = it.next()
for ; block != nil && err == consensus.ErrUnknownAncestor; block, err = it.next() {
if err := bc.addFutureBlock(block); err != nil {
return it.index, events, coalescedLogs, err
}
}
}
// Append a single chain head event if we've progressed the chain
if lastCanon != nil && bc.CurrentBlock().Hash() == lastCanon.Hash() {
events = append(events, ChainHeadEvent{lastCanon})
}
return it.index, events, coalescedLogs, err
}
这段代码处理了两个问题,一个是如果chain中还有未处理的区块,则看看是否是futureBlock,如果是则将它们加入到FutureBlocks字段中;另一个是检查主链最新的区块(CurrentBlock)是否发生了变化,如果是则生成一个ChainHeadEvent事件。
看完了insertChain,我们再来看看侧链是如何插入的,即insertSidechain。我们分两部分来分析这个方法里的代码,先看第一部分:
func (bc *BlockChain) insertSidechain(it *insertIterator) (int, []interface{}, []*types.Log, error) {
var (
externTd *big.Int
current = bc.CurrentBlock()
)
block, err := it.current(), consensus.ErrPrunedAncestor
for ; block != nil && (err == consensus.ErrPrunedAncestor); block, err = it.next() {
// Check the canonical state root for that number
if number := block.NumberU64(); current.NumberU64() >= number {
if canonical := bc.GetBlockByNumber(number); canonical != nil && canonical.Root() == block.Root() {
// 处理 shadow-state attack
log.Warn("Sidechain ghost-state attack detected", ......)
}
}
if externTd == nil {
externTd = bc.GetTd(block.ParentHash(), block.NumberU64()-1)
}
externTd = new(big.Int).Add(externTd, block.Difficulty())
if !bc.HasBlock(block.Hash(), block.NumberU64()) {
if err := bc.WriteBlockWithoutState(block, externTd); err != nil {
return it.index, nil, nil, err
}
}
}
......
}
insertSidechain开始的代码使用一个for循环将所有父区块被修剪过的区块(ErrPrunedAncestor)写入数据库中,写入的方法是WriteBlockWithoutState,即只写入区块数据,没有state数据。
这里需要注意的是有一个”shadow-state attach”检查。其判断逻辑是侧链上某区块的state哈希与主链上同样高度的区块的state哈希相同,这会导致侧链上的区块也可以拥有完整的state对象。但这仅仅可能是一个问题,因为有些情况下这确实是会发生的,比如一直没有交易发生,state对象的哈希一直没变过。
接下来我们再看看insertSidechain的第二部分代码:
func (bc *BlockChain) insertSidechain(it *insertIterator) (int, []interface{}, []*types.Log, error) {
......
//判断当前的侧链是否有资格成为主链
localTd := bc.GetTd(current.Hash(), current.NumberU64())
if localTd.Cmp(externTd) > 0 {
return it.index, nil, nil, err
}
//可以成为主链。
//收集当前分支上最新区块和其state对象不存在的祖先区块
var (
hashes []common.Hash
numbers []uint64
)
parent := bc.GetHeader(it.previous().Hash(), it.previous().NumberU64())
for parent != nil && !bc.HasState(parent.Root) {
hashes = append(hashes, parent.Hash())
numbers = append(numbers, parent.Number.Uint64())
parent = bc.GetHeader(parent.ParentHash, parent.Number.Uint64()-1)
}
if parent == nil {
return it.index, nil, nil, errors.New("missing parent")
}
//将这些收集到的区块重新调用insertChain,以将其加入到主链中
//这里为了防止内存占用过多,会记录内存使用的情况,如果超过一定限制就先调用一下insertChain。
var (
blocks []*types.Block
memory common.StorageSize
)
for i := len(hashes) - 1; i >= 0; i-- {
// Append the next block to our batch
block := bc.GetBlock(hashes[i], numbers[i])
blocks = append(blocks, block)
memory += block.Size()
if len(blocks) >= 2048 || memory > 64*1024*1024 {
if _, _, _, err := bc.insertChain(blocks, false); err != nil {
return 0, nil, nil, err
}
blocks, memory = blocks[:0], 0
}
}
if len(blocks) > 0 {
return bc.insertChain(blocks, false)
}
return 0, nil, nil, nil
}
这部分的逻辑也比较简单,上面的中文注释将代码分成了三部分。第一部分检查当前侧链是否有可能成为主链。如果是的话,第二部分从最新区块开始,收集所有没有state对象的区块。第三部分重新调用insertChain以调整分支成为主链。
到此一组区块的插入过程就结束了。我们对整个过程再进行一个总结:
- 调用
engine.VerifyHeaders对所有区块头进行异步验证 - 检查第一个区块的验证结果,根据不同错误值进行不同的处理。可能将这组区块加入侧链中,也可能加入futureBlock中;可能忽略已知区块,也可能有其它未知错误直接返回。
- 对于所有验证正常的区块,调用
processor.Process生成state对象有和收据(receipt),并验证state对象。验证成功后调用writeBlockWithState将区块、state对象和收据写入数据库中。 writeBlockWithState除了将相关数据写入数据库中外,还会对主链与侧链进行判断和重新调整。- 根据
writeBlockWithState返回的信息,生成对应的消息事件。 - 对于第3步中剩余的区块,判断是否是futureBlock,如果是则将其加入
futureBlocks中。
侧链的插入过程总结如下:
- 对于所有区块,进行”shadow-state attack”检查。
- 检查通过后调用
WriteBlockWithoutState将区块写入数据库中。 - 所有区块处理完成后,判断当前侧链是否有资格成为主链。如果是,则将所有缺少state的父区块重新调用
insertChain,以将当前分支改成主链。
三种同步模式
虽然区块同步不是我们本篇文章要讲的内容,但不同的同步方式涉及到的区块操作方式也有所不同,因此我们这一小节里看看不同的区块同步模式对应在blockchain模块中是如何操作的。
以太坊的区块有三种同步模式,分别是:full、fast、ligth,我们分别看一下不同模式的区块操作。
full mode
顾名思议,“full mode”同步所有的区块数据。在full模式下,同步模块调用BlockChain.InsertChain向数据库中插入从别它节点获取到的区块数据。而在BlockChain.InsertChain中,会逐个计算和验证每个块的state和recepits等数据,如果一切正常就将同步而来的区块数据以及自己计算得到的state、recepits数据一起写入到数据库中。
注意在full模式有两种处理方式,其中一种保存所有历史数据,这种节点被称为”archive node”。另一个则对state进行修剪。想要成为一个“archive node”,设置配置文件中NoPruning字段为true即可。
fast mode
所谓的“快速模式”,是相对于”full mode”来说的。在full模式下,state和recepits是根据区块数据中的交易在当前机器上计算出来的。而在fast模式下,state和recepits不再由本地计算,而是和区块数据一样,直接从其它节点中同步。因此在fast模式下,同步模式调用BlockChain.InsertReceiptChain将同步到的区块和recepits直接写入到blockchain数据库中;而state也会通过stateDb直接写入到库中。
在BlockChain中有一个currentFastBlock字段,代表的是fast模式下主链上的最新块。
可以看出,fast模式通过使用网络直接同步的方式替换了full模式下本地自己计算state和recepits的方式,是用网络带宽替换了本地的计算资源。
ligth mode
light模式也叫做轻模式,是一种只同步区块头的模式。在light模式下,区块链的组织不使用blockchain模块,而是使用light模块。此模块位于以太坊项目下的”light”目录。与blockchain模块最大的区别在于,light模块只调用了HeaderChain的相关方法对区块头进行处理,而不处理其它数据。只有当需要用到某区块除头部以外的其它数据时,才去获取需要的数据。
调用loadLastState时,如果currentBlock的state不存在,则调用repair获取顺着currentBlock往上找,直到有一个state存在的。
总结
本篇文章主要介绍了以太坊的区块链模块。以太坊的区块链有主链、侧链、叔块等概念,还会对state进行修剪。在区块插入过程中,还需要及对主链与侧链进行判断和调整。
区块链模块中还有一些细节代码没能全部在文章中介绍,但相信了解了本篇文章介绍的一些概念和功能,会非常容易读懂其它细节。如果文章中有不对的地方,感谢您不吝指正。
原文始发于fatcat22:以太坊源码解析:blockchain