原文始发于Freebuf(上海控安):基于机器学习的汽车CAN总线异常检测方法
作者 | 张渊策 上海控安可信软件创新研究院研发工程师来源 |鉴源实验室
目前机器学习是研究车辆网络入侵检测技术的热门方向,通过引入机器学习算法来识别车载总线上的网络报文,可实现对车辆已知/未知威胁的入侵检测。这种基于机器学习的异常检测技术普适性较强,无需对适配车型进行定制化开发,但存在异常样本采集数量大和训练难度高的问题。本文将结合个人经验对基于机器学习的汽车CAN总线异常检测方法展开具体介绍。
01 车载异常检测流程
基于机器学习的车载异常检测的整体流程如图1所示,其中关键环节包括输入数据、数据预处理、训练及测试算法、评估及优化。
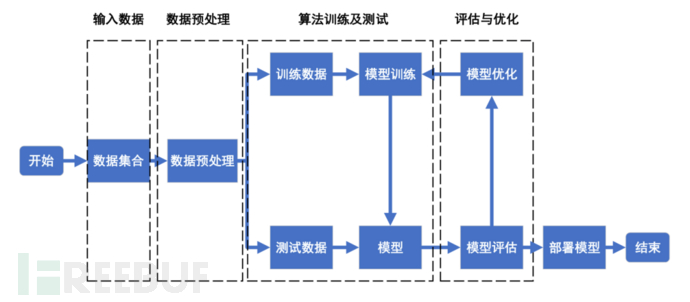
图1 基于机器学习的车载异常检测整体流程
02 数据源
针对特定车型进行数据的采集,形成有特点的定制化数据集,并用此数据集进行智能算法的训练与验证。在实际应用中,工程师可以直接采用公开数据集作为模型训练的数据,也可以通过实际采集车辆真实数据来获取数据集。
公开数据集:公开数据集CAR-HACKING DATASET[1]中提供了汽车黑客数据,如图2所示,其中包括 DoS 攻击、模糊攻击、驱动齿轮欺骗攻击和RPM仪表欺骗攻击四种类别的数据。该数据集是通过在执行消息注入攻击时利用真实车辆的OBD-II端口记录CAN流量来构建的。其数据集特征包括Timestamp,CAN ID,DLC(数据长度码),data(CAN数据字段),Flag(T或R,T代表注入信息,R代表正常信息)。公开数据集一般是经过公开验证的,更具有通用性和代表性,便于进行不同算法异常检测效果的比对。
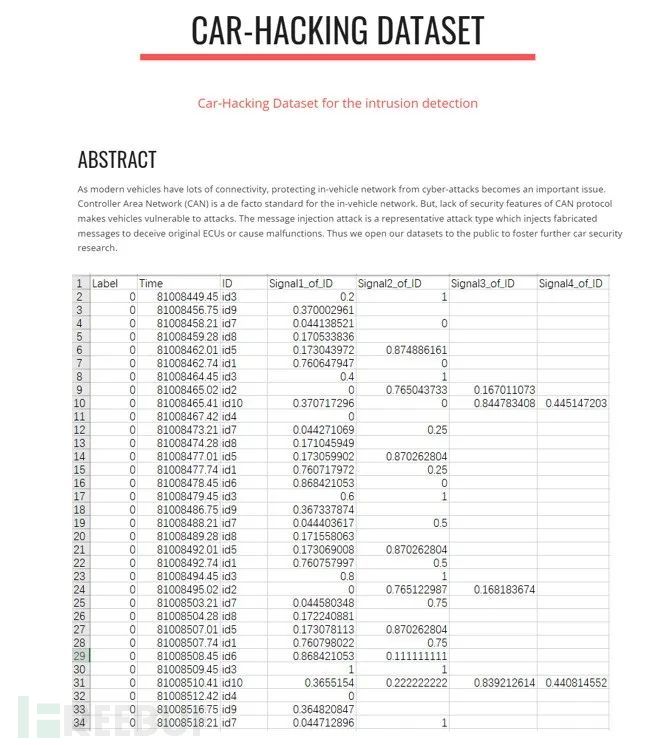
图2 CAR-HACKING DATASET[1]
实车数据集:数据源还可以通过实车采集的方式获取,通过向车内注入特定的攻击,并使用CAN采集工具对实车数据中的报文数据进行采集,采集时需要注意采集时间要尽可能平均。由此得到的实车数据集更加真实,其中可能包含一些公开数据集无法覆盖的异常场景。此外,实车数据采集得到的数据集通常还需要进行预处理工作。
2.1 数据预处理
机器学习算法模型的质量很大程度取决于数据的质量。原始数据往往不利于模型的训练,因此需要进行数据预处理以提高数据的质量,使其更好地适用模型。数据预处理过程一般包括特征选取、数据标准化及特征编码,如图3所示。在实际车载异常检测应用中,最终选用的数据预处理方法通常会根据智能算法的不同而有所差异。
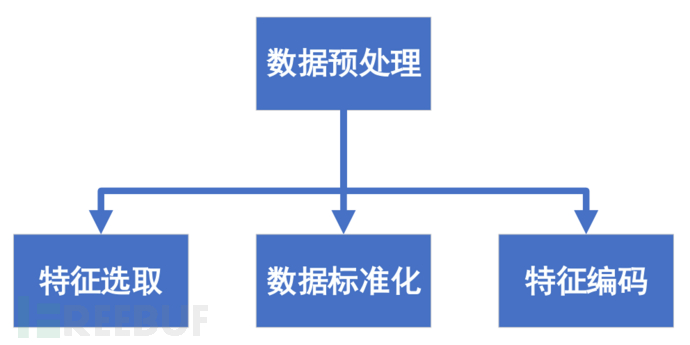
图3 数据处理过程
2.2 特征选取
CAN报文的特征及描述如表1所示。记录每一条数据的时间标识Time,每一条报文的序号为CAN ID,相同CAN ID报文出现的时间间隔为period。Payload部分通常将十六进制的信息转换为十进制,根据CAN报文的特点,将payload划分为8个特征位(byte0,byte1, byte2, byte3, byte4, byte5, byte6, byte7),它们全部分布在0~255之间。
一般输入数据格式为Dataframe格式,对应的特征是Dataframe的列名称。在进行不同算法的训练时,选取包含指定特征值(某些列)的Dataframe进行后续数据标准化的操作。

表1 CAN报文特征
2.3 数据标准化
车载网络报文的数据信号(数据payload部分)具有不同的量纲和取值范围,通过标准化,在不改变样本数据分布的同时,使得这些数值信号能够进行比较。对于利用梯度下降的模型,数值型数据进行标准化可以削弱不同特征对模型的影响差异,使得梯度下降能更快地找到最优解,同时结果更可靠。对于决策树这类不通过梯度下降而利用信息增益比的算法,则不需要进行数据标准化,整体流程如图4所示。
标准化对样本的payload特征分别进行计算使其满足正态分布,Z= (x- μ)/σ。一般情况下,标准化与数据分布相关,具有更强的统计意义,在车载入侵检测数据的处理上更加通用合适。对于需要数据标准化的算法,使用Scikit-learn中
preprocessing.StandardScaler(df)函数,df为需要标准化的数据(只含有payload部分的Dataframe),得到标准化后的数据特征编码或直接进行训练。

图4 数据标准化流程
2.4 特征编码
车载网络报文中,数据场以外还存在一部分报文内容,如CAN ID。对于很多机器学习算法,分类器往往默认数据是连续的,并且是有序的,因此需要对此类特征进行编码。对于维度较低的特征可以直接使用独热编码。对于维度较高的特征,可以使用二进制编码。
独热编码是用等同于状态数量的维度进行编码,每种状态下的独热编码只有其中一位为1,其余均为0。编码后的特征互斥,每次只有一个激活,有利于模型处理数据。
输入数据集,如CAN ID经过one_hot(df)函数,将输入数据进行one-hot编码。一个CAN ID将变为16*3的向量,如图5所示。该向量将作为训练模型的输入,进行后续的模型训练工作。
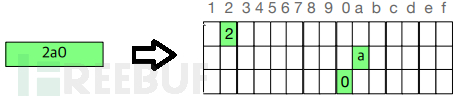
图5 CAN ID 特征编码[1]
03 算法训练及测试
3.1 数据集划分
输入数据集以7:1.5:1.5的比例划分成训练集、验证集和测试集。训练集数据只用来训练模型,其数据不出现在算法测试中。验证集主要是用来反映训练得到模型的相关效果,也会在其上进行算法模型的优化与调试,反复验证直到达到最佳效果。测试集主要表现模型的最终效果,测试集数据也是用来评价模型的数据,测试集数据不出现在算法训练中。
数据集划分流程如图6所示,首先输入数据采用Scikit-learn中
model_selection.train_test_split()函数,此函数可以将数据集先划分成7:3的训练集和测试数据,然后再将测试数据集划分成5:5的验证集与测试集。
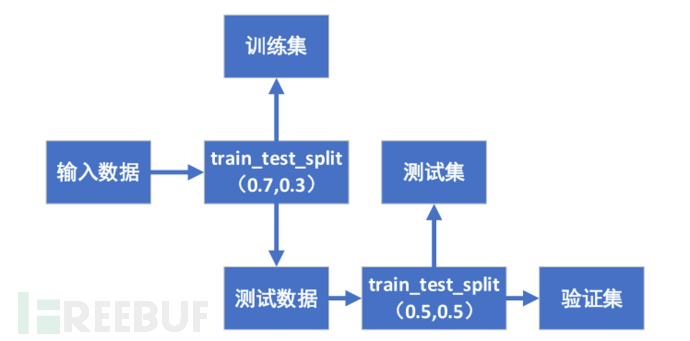
图6 数据集划分流程
3.2 SMOTE采样
对于采集到的车载网络数据,攻击报文数量远少于正常报文,造成了样本类别不平衡。机器学习中往往假定训练样本各类别是同等数量,即各类样本数目是均衡的。一般来说,不平衡样本会导致训练模型侧重样本数目较多的类别,而“轻视”样本数目较少类别,这样模型在测试数据上的泛化能力就会受到影响。通过SMOTE[2](合成少数类过采样技术),在少数类别样本之间进行插值生成新的样本,如图7。相比随机过采样,SMOTE大大降低了过拟合的可能。
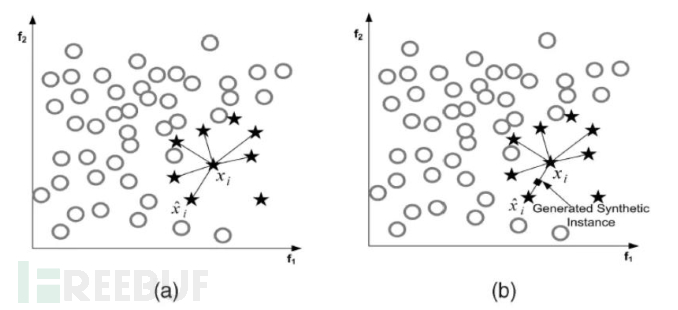
图7 SMOTE采样原理 [2]
在训练模型前对各类别的训练数据进行SMOTE过采样的操作,SMOTE过采样流程如图8。使用imblearn.over_sampling中的SMOTE().fit_resample(X,Y)函数,其中X为输入需要训练的报文集合,Y为X中每一条报文的类别。经过SMOTE处理,各类别的报文数量会变得一样多,可以进行下一步的操作。

图8 SMOTE采样流程
3.3 模型训练
模型训练是从标签化训练数据集中推断出函数的机器学习任务。常用的模型训练算法包括RNN(Recurrent Neural Network,循环神经网络)、LSTM(Long Short-Term Memory,长短期记忆网络)、GRU(Gated Recurrent Units,门控循环神经网络)、DCNN(Dynamic Convolution Neural Network,深度卷积神经网络)、SVM(Support Vector Machine,支持向量机)、DT(Decision Tree,决策树)、RF(Random Forest,随机森林)、XGBoost(Extreme Gradient Boosting,极端梯度提升)、Stacking(集成学习算法)、Clustering(聚类)等。
04 评估与优化
模型的总体优化流程如图9所示,对模型测试的结果进行评估,根据评估的结果进一步优化模型。下面详细阐述评估指标和优化方式。
4.1 评估指标
方案使用平均准确率、P-R曲线、F-score对模型进行评价。平均准确率是判断入侵检测算法优劣的最直观的评价标准。P-R曲线和F-score能更加直观地反映入侵检测模型在特定数据集上的表现。本方案选择平均准确率作为模型在验证集上的评价指标,在超参数调优时,根据平均准确率选择更优超参数组合。本方案选择F-score作为模型在测试集上的评价指标,评价最终的模型效果。
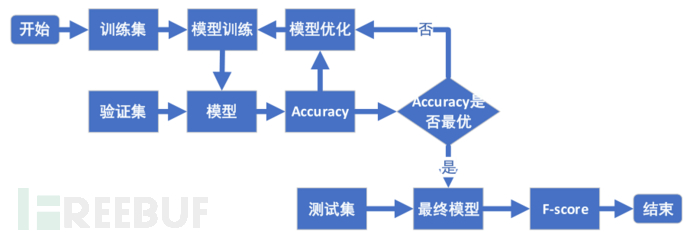
图9 模型优化流程
a)准确率 Accuracy
准确率公式为:
Accuracy = (TP + TN) / (TP + TN + FP + FN)
其中,TP(true positive)是正例,代表被模型正确地预测为正类别的样本。例如,模型推断出某条报文是攻击报文,而该报文确实是攻击报文。TN(true negative)为假正例,代表被模型正确地预测为负类别的样本。例如,模型推断出某条报文不是攻击报文,而该报文确实不是攻击报文。FN (false negative)是假负例,代表被模型错误地预测为负类别的样本。例如,模型推断出某条报文不是攻击报文(负类别),但该条报文其实是攻击报文。FP(false positive)为假正例,代表被模型错误地预测为正类别的样本。例如,模型推断出某条报文是攻击报文(正类别),但该条报文其实不是攻击报文。
准确率是指分类正确的样本占总样本个数的比例。在不同类别的样本比例非常不均衡时,占比大的类别将成为影响准确率的主要因素。导致模型整体准确率很高,但是不代表对小占比类别的分类效果很好。因此,使用平均准确率,即每个类别下的样本准确率的算术平均作为模型评估的指标。
在超参数选择阶段,算法会根据各个超参数的准确率Accuracy,进行选择。选择准确率最高的超参数作为模型使用的超参数。
b)P-R曲线和F-score
精确率P = TP / (TP+FP),指分类正确的正样本个数占分类器判定为正样本的样本个数的比例。召回率R = TP / (TP+FN),指分类正确的正样本个数占真正的正样本个数的比例。通过F-score进行定量分析,同时考虑了精确率和召回率。
F-score =(1+β^2 )*P*R/(β^2*P+R)
智能分析使用F1-score作为指标,评价最终模型在测试集上的表现效果。
4.2 模型优化
入侵检测使用到的机器学习和神经网络模型包含大量的超参数,超参数直接影响了模型的优劣,寻找超参数的最优取值是至关重要的问题。通过超参数优化方法和K折交叉验证,找到最优的超参数,使模型能够准确地判断报文类型。
a)K折交叉验证
K折交叉验证用于模型调优,测试模型预测未用于估计的新数据的能力,找到使得模型泛化性能最优的超参值。具体原理如图10,将训练数据分成K份,用其中的(K-1)份训练模型,剩余的1份数据用于评估模型。循环迭代K次,并对得到的K个评估结果取平均值,得到最终的结果。
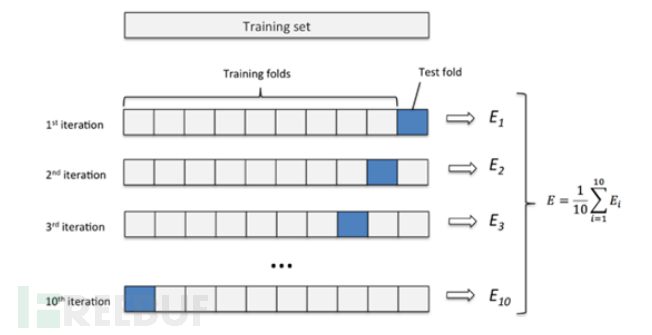
图10 K折交叉验证原理[3]
K值越小,模型越偏差越低、方差越高,容易出现过拟合。K值越大,则偏差提高,方差降低,且计算开销增大。在训练中我们一般选择k=5。使用下面函数进行K折交叉验证划分,sklearn.model_selection.KFold(n_splits=5,shuffle=True,random_state=999).split(df),其中n_splits为交叉验证的折数,shuffle表示是否打乱数据,random_state为随机种子,df为训练数据。
b)超参数优化
超参数优化方法主要有:网格搜索和贝叶斯优化。
网格搜索:以穷举的方式遍历所有可能的参数组合,网格搜索在1维、2维、3维的搜索空间表现相对来说不错,很容易覆盖到空间的大部分,而且耗时不大。使用sklearn.model_selection中的GridSearchCV ()进行超参数选择和交叉验证。
贝叶斯优化:网格搜索和随机搜索没有利用已搜索点的信息,使用这些信息指导搜索过程可以提高结果的质量以及搜索的速度。贝叶斯优化利用之前已搜索点的信息确定下一个搜索点,用于求解维数不高的黑盒优化问题。它的本质其实是一种回归模型,即利用回归模型预测的函数值来选择下一个搜索点。使用hyperopt中的fmin()函数进行贝叶斯优化,给出最优模型参数。
以训练集的交叉验证结果作为性能度量。根据模型的超参数数量、取值范围、性能影响等因素,选择不同的超参数优化方法,对模型进行参数优化。
05 小结
面向智能网联汽车无线通信系统、车载娱乐系统、驾驶辅助系统以及典型智能网联场景,机器学习作为车载网络入侵检测中至关重要的一项技术,可实现对已知/未知攻击行为的特征识别检测,最终助力车端和云端安全联动,保障车载网络的信息安全。
参考文献:
[1] Seo, Eunbi, Hyun Min Song, and Huy Kang Kim. “GIDS: GAN based intrusion detection system for in-vehicle network.” 2018 16th Annual Conference on Privacy, Security and Trust (PST). IEEE, 2018.
[2] He H, Garcia E A. Learning from imbalanced data[J]. IEEE Transactions on knowledge and data engineering, 2009, 21(9): 1263-1284.
[3] Ashfaque J M, Iqbal A. Introduction to support vector machines and kernel methods[J]. publication at https://www. researchgate. net/publication/332370436, 2019.
相关文章
暂无评论...