publicstaticclassPersonimplementsandroid.os.Parcelable{publicjava.lang.Stringname;publicintage=0;publicbooleangender=false;publicstaticfinalandroid.os.Parcelable.Creator<Person>CREATOR=newandroid.os.Parcelable.Creator<Person>(){@OverridepublicPersoncreateFromParcel(android.os.Parcel_aidl_source){Person_aidl_out=newPerson();_aidl_out.readFromParcel(_aidl_source);return_aidl_out;}@OverridepublicPerson[]newArray(int_aidl_size){returnnewPerson[_aidl_size];}};@OverridepublicfinalvoidwriteToParcel(android.os.Parcel_aidl_parcel,int_aidl_flag){int_aidl_start_pos=_aidl_parcel.dataPosition();_aidl_parcel.writeInt(0);_aidl_parcel.writeString(name);_aidl_parcel.writeInt(age);_aidl_parcel.writeInt(((gender)?(1):(0)));int_aidl_end_pos=_aidl_parcel.dataPosition();_aidl_parcel.setDataPosition(_aidl_start_pos);_aidl_parcel.writeInt(_aidl_end_pos-_aidl_start_pos);_aidl_parcel.setDataPosition(_aidl_end_pos);}publicfinalvoidreadFromParcel(android.os.Parcel_aidl_parcel){int_aidl_start_pos=_aidl_parcel.dataPosition();int_aidl_parcelable_size=_aidl_parcel.readInt();try{if(_aidl_parcelable_size<4)thrownewandroid.os.BadParcelableException("Parcelable too small");;if(_aidl_parcel.dataPosition()-_aidl_start_pos>=_aidl_parcelable_size)return;name=_aidl_parcel.readString();if(_aidl_parcel.dataPosition()-_aidl_start_pos>=_aidl_parcelable_size)return;age=_aidl_parcel.readInt();if(_aidl_parcel.dataPosition()-_aidl_start_pos>=_aidl_parcelable_size)return;gender=(0!=_aidl_parcel.readInt());}finally{if(_aidl_start_pos>(Integer.MAX_VALUE-_aidl_parcelable_size)){thrownewandroid.os.BadParcelableException("Overflow in the size of parcelable");}_aidl_parcel.setDataPosition(_aidl_start_pos+_aidl_parcelable_size);}}@OverridepublicintdescribeContents(){int_mask=0;return_mask;}}
status_tParcel::finishWrite(size_tlen){if(len>INT32_MAX){// don't accept size_t values which may have come from an
// inadvertent conversion from a negative int.
returnBAD_VALUE;}//printf("Finish write of %d\n", len);
mDataPos+=len;ALOGV("finishWrite Setting data pos of %p to %zu",this,mDataPos);if(mDataPos>mDataSize){mDataSize=mDataPos;ALOGV("finishWrite Setting data size of %p to %zu",this,mDataSize);}//printf("New pos=%d, size=%d\n", mDataPos, mDataSize);
returnNO_ERROR;}
而如果当前缓冲区的内存不足,则会使用 growData 方法进行更新:
status_tParcel::growData(size_tlen){if(len>INT32_MAX){// don't accept size_t values which may have come from an
// inadvertent conversion from a negative int.
returnBAD_VALUE;}if(len>SIZE_MAX-mDataSize)returnNO_MEMORY;// overflow
if(mDataSize+len>SIZE_MAX/3)returnNO_MEMORY;// overflow
size_tnewSize=((mDataSize+len)*3)/2;return(newSize<=mDataSize)?(status_t)NO_MEMORY:continueWrite(std::max(newSize,(size_t)128));}
if(desired>mDataCapacity){uint8_t*data=reallocZeroFree(mData,mDataCapacity,desired,mDeallocZero);if(data){LOG_ALLOC("Parcel %p: continue from %zu to %zu capacity",this,mDataCapacity,desired);gParcelGlobalAllocSize+=desired;gParcelGlobalAllocSize-=mDataCapacity;mData=data;mDataCapacity=desired;}else{mError=NO_MEMORY;returnNO_MEMORY;}}
staticvoidandroid_os_Parcel_writeString16(JNIEnv*env,jclassclazz,jlongnativePtr,jstringval){Parcel*parcel=reinterpret_cast<Parcel*>(nativePtr);if(parcel!=nullptr){status_terr=NO_ERROR;if(val){// NOTE: Keep this logic in sync with Parcel.cpp
constsize_tlen=env->GetStringLength(val);constsize_tallocLen=len*sizeof(char16_t);err=parcel->writeInt32(len);char*data=reinterpret_cast<char*>(parcel->writeInplace(allocLen+sizeof(char16_t)));if(data!=nullptr){env->GetStringRegion(val,0,len,reinterpret_cast<jchar*>(data));*reinterpret_cast<char16_t*>(data+allocLen)=0;}else{err=NO_MEMORY;}}else{err=parcel->writeString16(nullptr,0);}if(err!=NO_ERROR){signalExceptionForError(env,clazz,err);}}}
status_tParcel::writeFileDescriptor(intfd,booltakeOwnership){// ...
switch(rpcFields->mSession->getFileDescriptorTransportMode()){caseRpcSession::FileDescriptorTransportMode::UNIX:caseRpcSession::FileDescriptorTransportMode::TRUSTY:{if(status_terr=writeInt32(RpcFields::TYPE_NATIVE_FILE_DESCRIPTOR);err!=OK){returnerr;}if(status_terr=writeInt32(rpcFields->mFds->size());err!=OK){returnerr;}}}flat_binder_objectobj;obj.hdr.type=BINDER_TYPE_FD;obj.flags=0;obj.binder=0;/* Don't pass uninitialized stack data to a remote process */obj.handle=fd;obj.cookie=takeOwnership?1:0;returnwriteObject(obj,true);}
voidwriteToParcelInner(Parcelparcel,intflags){// Keep implementation in sync with writeToParcel() in
// frameworks/native/libs/binder/PersistableBundle.cpp.
finalArrayMap<String,Object>map;synchronized(this){// ...
}// Special case for empty bundles.
if(map==null||map.size()<=0){parcel.writeInt(0);return;}intlengthPos=parcel.dataPosition();parcel.writeInt(-1);// dummy, will hold length
parcel.writeInt(BUNDLE_MAGIC);intstartPos=parcel.dataPosition();parcel.writeArrayMapInternal(map);intendPos=parcel.dataPosition();// Backpatch length
parcel.setDataPosition(lengthPos);intlength=endPos-startPos;parcel.writeInt(length);parcel.setDataPosition(endPos);}
writeArrayMapInternal 则主要实现 Bundle 内部字典数据的写入:
voidwriteArrayMapInternal(@NullableArrayMap<String,Object>val){if(val==null){writeInt(-1);return;}// Keep the format of this Parcel in sync with writeToParcelInner() in
// frameworks/native/libs/binder/PersistableBundle.cpp.
finalintN=val.size();writeInt(N);intstartPos;for(inti=0;i<N;i++){writeString(val.keyAt(i));writeValue(val.valueAt(i));}}
publicfinalvoidwriteValue(@NullableObjectv){if(v==null){writeInt(VAL_NULL);}elseif(vinstanceofString){writeInt(VAL_STRING);writeString((String)v);}elseif(vinstanceofInteger){writeInt(VAL_INTEGER);writeInt((Integer)v);}elseif(vinstanceofMap){writeInt(VAL_MAP);writeMap((Map)v);}// ....
else{Class<?>clazz=v.getClass();if(clazz.isArray()&&clazz.getComponentType()==Object.class){// Only pure Object[] are written here, Other arrays of non-primitive types are
// handled by serialization as this does not record the component type.
writeInt(VAL_OBJECTARRAY);writeArray((Object[])v);}elseif(vinstanceofSerializable){// Must be last
writeInt(VAL_SERIALIZABLE);writeSerializable((Serializable)v);}else{thrownewRuntimeException("Parcel: unable to marshal value "+v);}}}
// Keep in sync with frameworks/native/include/private/binder/ParcelValTypes.h.
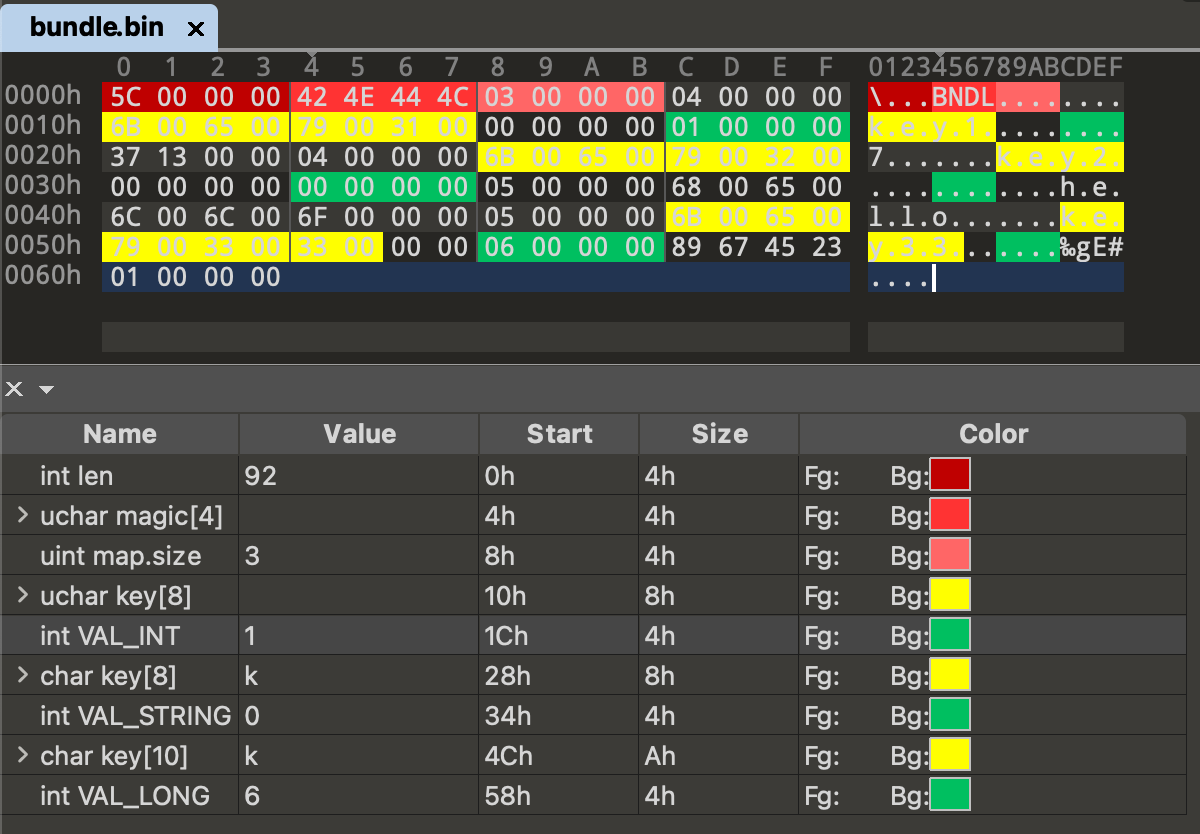
privatestaticfinalintVAL_NULL=-1;privatestaticfinalintVAL_STRING=0;privatestaticfinalintVAL_INTEGER=1;privatestaticfinalintVAL_MAP=2;privatestaticfinalintVAL_BUNDLE=3;privatestaticfinalintVAL_PARCELABLE=4;privatestaticfinalintVAL_SHORT=5;privatestaticfinalintVAL_LONG=6;privatestaticfinalintVAL_FLOAT=7;privatestaticfinalintVAL_DOUBLE=8;privatestaticfinalintVAL_BOOLEAN=9;privatestaticfinalintVAL_CHARSEQUENCE=10;privatestaticfinalintVAL_LIST=11;privatestaticfinalintVAL_SPARSEARRAY=12;privatestaticfinalintVAL_BYTEARRAY=13;privatestaticfinalintVAL_STRINGARRAY=14;privatestaticfinalintVAL_IBINDER=15;privatestaticfinalintVAL_PARCELABLEARRAY=16;privatestaticfinalintVAL_OBJECTARRAY=17;privatestaticfinalintVAL_INTARRAY=18;privatestaticfinalintVAL_LONGARRAY=19;privatestaticfinalintVAL_BYTE=20;privatestaticfinalintVAL_SERIALIZABLE=21;privatestaticfinalintVAL_SPARSEBOOLEANARRAY=22;privatestaticfinalintVAL_BOOLEANARRAY=23;privatestaticfinalintVAL_CHARSEQUENCEARRAY=24;privatestaticfinalintVAL_PERSISTABLEBUNDLE=25;privatestaticfinalintVAL_SIZE=26;privatestaticfinalintVAL_SIZEF=27;privatestaticfinalintVAL_DOUBLEARRAY=28;
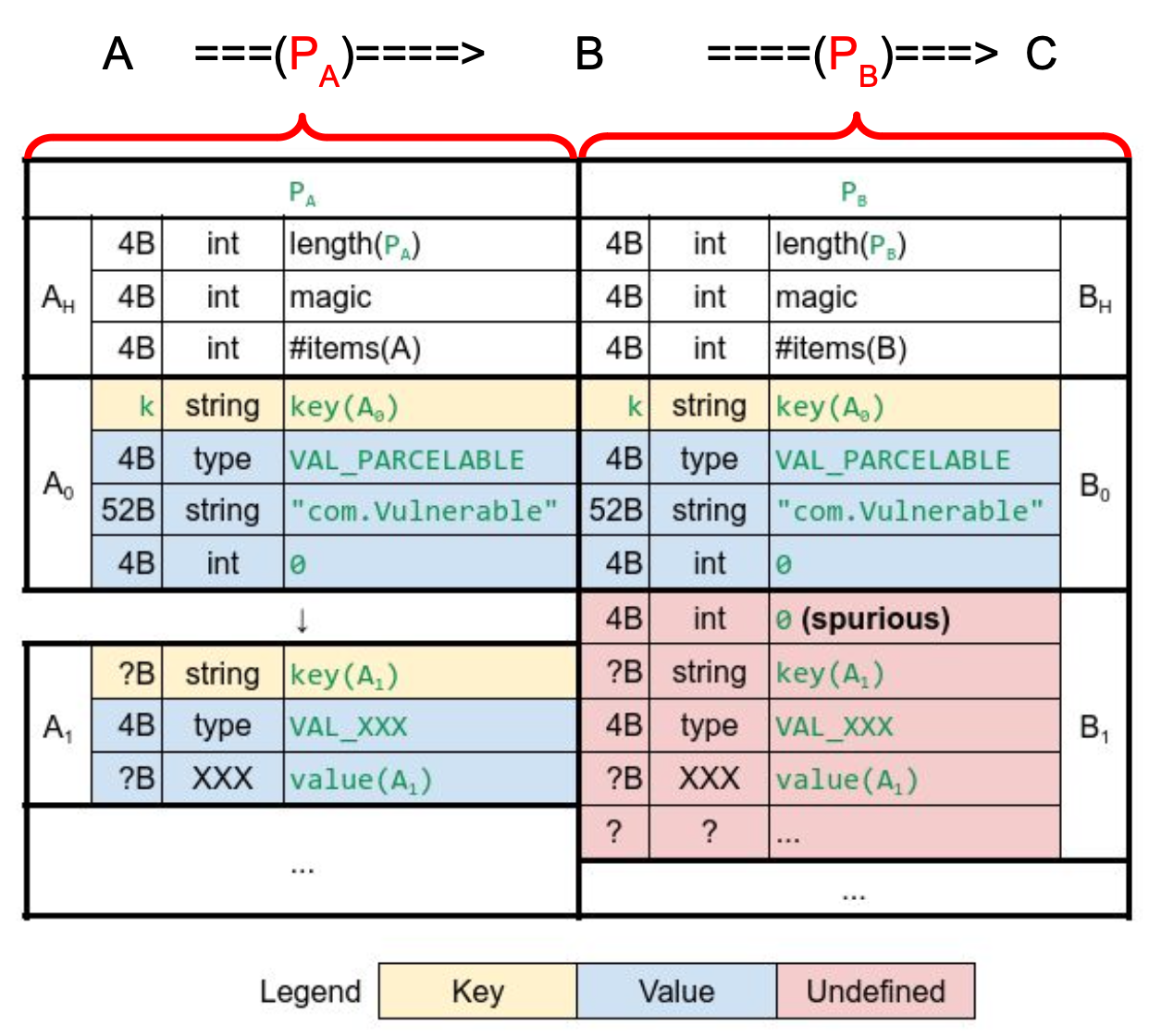
假设服务端 B 接收我们的 Bundle 数据进行反序列化后再次序列化发送给服务端 C,而我们的 bundle 中带有一个类型为 Vunerable 的 key,那在 B 接收到数据后再发出去的数据会如下图右边所示,其中本该是 Int 的字段被写成了 Long,导致 C 再次反序列化时候对后续数据的解析出现异常:
From: Android Parcels: The Bad, the Good and the Better – Introducing Android’s Safer Parcel
通过精心构造发送给 B 的数据,我们可以令 B 和 C 都能正常序列化出 Bundle 对象,甚至让这两个 Bundle 含有不同的 key!
在大部分情况下,溢出的部分是 Long 数据的高有效位,因此会是 0,如果此时第二次反序列化处理到这里,会认为这有个 key 长度为 0 的元素,查看读取字符串相关的代码,如下所示:
constchar16_t*Parcel::readString16Inplace(size_t*outLen)const{int32_tsize=readInt32();// watch for potential int overflow from size+1
if(size>=0&&size<INT32_MAX){*outLen=size;constchar16_t*str=(constchar16_t*)readInplace((size+1)*sizeof(char16_t));if(str!=nullptr){if(str[size]==u'\0'){returnstr;}android_errorWriteLog(0x534e4554,"172655291");}}*outLen=0;returnnullptr;}
packageandroid.hardware.camera2.params;publicfinalclassOutputConfigurationimplementsParcelable{privateOutputConfiguration(@NonNullParcelsource){introtation=source.readInt();intsurfaceSetId=source.readInt();// ...
booleanisMultiResolution=source.readInt()==1;// New in Android 12
ArrayList<Integer>sensorPixelModesUsed=newArrayList<Integer>();// New in Android 12
source.readList(sensorPixelModesUsed,Integer.class.getClassLoader());// New in Android 12
// ...
}publicstaticfinal@android.annotation.NonNullParcelable.Creator<OutputConfiguration>CREATOR=newParcelable.Creator<OutputConfiguration>(){@OverridepublicOutputConfigurationcreateFromParcel(Parcelsource){try{OutputConfigurationoutputConfiguration=newOutputConfiguration(source);returnoutputConfiguration;}catch(Exceptione){Log.e(TAG,"Exception creating OutputConfiguration from parcel",e);returnnull;}}};}
其中第一个 intent 是 A 应用指定的 sendBroadcast 的参数,第二个参数则是 system_server 传递给应用 B 的。漏洞利用思路就是通过 intent 参数的反序列化数据残留,间接地修改 info 参数,因为应用 B 会使用 ActivityInfo 中的数据去实例化代码,具体来说就是:
publicfinalvoidrecycle(){if(mRecycled){Log.wtf(TAG,"Recycle called on unowned Parcel. (recycle twice?) Here: "+Log.getStackTraceString(newThrowable())+" Original recycle call (if DEBUG_RECYCLE): ",mStack);return;}mRecycled=true;// We try to reset the entire object here, but in order to be
// able to print a stack when a Parcel is recycled twice, that
// is cleared in obtain instead.
mClassCookies=null;freeBuffer();if(mOwnsNativeParcelObject){synchronized(sPoolSync){if(sOwnedPoolSize<POOL_SIZE){mPoolNext=sOwnedPool;sOwnedPool=this;sOwnedPoolSize++;}}}else{mNativePtr=0;synchronized(sPoolSync){if(sHolderPoolSize<POOL_SIZE){mPoolNext=sHolderPool;sHolderPool=this;sHolderPoolSize++;}}}}
diff --git a/core/java/android/os/BaseBundle.java b/core/java/android/os/BaseBundle.java
index 0418a4b..b599028 100644
--- a/core/java/android/os/BaseBundle.java
+++ b/core/java/android/os/BaseBundle.java
@@ -438,8 +438,11 @@
map.ensureCapacity(count);
}
try {
+ // recycleParcel being false implies that we do not own the parcel. In this case, do
+ // not use lazy values to be safe, as the parcel could be recycled outside of our
+ // control.
recycleParcel &= parcelledData.readArrayMap(map, count, !parcelledByNative,
- /* lazy */ true, mClassLoader);
+ /* lazy */ recycleParcel, mClassLoader);
} catch (BadParcelableException e) {
if (sShouldDefuse) {
Log.w(TAG, "Failed to parse Bundle, but defusing quietly", e);
@@ -1845,7 +1848,6 @@
// bundle immediately; neither of which is obvious.
synchronized (this) {
initializeFromParcelLocked(parcel, /*recycleParcel=*/ false, isNativeBundle);
- unparcel(/* itemwise */ true);
}
return;
}
privatevoidreadFromParcelInner(Parcelparcel,intlength){finalintmagic=parcel.readInt();finalbooleanisJavaBundle=magic==BUNDLE_MAGIC;finalbooleanisNativeBundle=magic==BUNDLE_MAGIC_NATIVE;if(!isJavaBundle&&!isNativeBundle){thrownewIllegalStateException("Bad magic number for Bundle: 0x"+Integer.toHexString(magic));}if(parcel.hasReadWriteHelper()){// If the parcel has a read-write helper, it's better to deserialize immediately
// otherwise the helper would have to either maintain valid state long after the bundle
// had been constructed with parcel or to make sure they trigger deserialization of the
// bundle immediately; neither of which is obvious.
synchronized(this){initializeFromParcelLocked(parcel,/*recycleParcel=*/false,isNativeBundle);unparcel(/* itemwise */true);}return;}// 直接使用 Parcel.appendFrom 拷贝原 Parcel 的数据
Parcelp=Parcel.obtain();p.appendFrom(parcel,offset,length);mParcelledData=p;